小米声音理解大模型 MiDashengLM-7B 全开源,22 项评测登顶刷新纪录
小米大模型登顶22项评测,开启语音理解新纪元
8月4日,小米自主研发的声音理解大模型MiDashengLM-7B正式发布,并已全面开源。
根据小米官方介绍,MiDashengLM-7B在速度和精度上取得双重突破:单样本首Token延迟仅为同类模型的1/4,在相同显存条件下并发能力超过20倍。同时,在22个公开评测集上刷新了多模态大模型的最佳成绩(SOTA)。
MiDashengLM-7B 基于 Xiaomi Dasheng 作为音频编码器和 Qwen2.5-Omni-7B Thinker 作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
2024年,小米发布的Xiaomi Dasheng声音基座模型在国际上首次实现AudioSet50mAP的突破,成为首个在该指标上取得重大进展的中国技术方案。在HEARBenchmark环境中,该模型在环境声、语音和音乐三大领域均展现出显著优势,并持续保持领先地位。 这一成绩不仅体现了小米在音频AI领域的技术实力,也标志着中国企业在国际音频识别赛道上迈出了关键一步。随着人工智能技术的不断发展,声音识别作为人机交互的重要环节,正日益受到全球关注。小米此次的突破,无疑为行业树立了新的标杆,也为后续的技术创新提供了更多可能性。
Xiaomi Dasheng 在小米的智能家居和汽车座舱等场景有超过 30 项落地应用。行业首发的车外唤醒防御、手机音箱全天候监控异常声音、“打个响指”环境音关联 IoT 控制能力,以及小米 YU7 上搭载的增强哨兵模式划车检测等,背后都有 Xiaomi Dasheng 作为核心算法的赋能。
MiDashengLM 的训练数据由 100% 的公开数据构成,模型以宽松的 Apache License 2.0 发布,同时支持学术和商业应用。
小米表示,与Qwen2.5-Omni等未披露训练数据细节的模型不同,MiDashengLM全面公开了77个数据源的具体比例,其技术报告详细阐述了从音频编码器预训练到指令微调的整个流程。
作为小米“人车家全生态”战略的重要技术支撑,MiDashengLM具备融合理解语音、环境声音和音乐的跨领域能力,不仅能够识别用户所处的环境情况,还能深入分析其中的潜在含义,从而增强对用户场景的理解能力与泛化水平。
基于MiDashengLM的模型能够通过自然语言与用户进行交互,提供更加人性化的沟通与反馈服务。例如,在用户练习唱歌或学习外语时,可以给予发音方面的反馈,并制定个性化的提升方案;又如在用户驾驶车辆时,能够实时解答用户对周围环境声音的疑问。
MiDashengLM以XiaomiDasheng音频编码器为核心,是XiaomiDasheng系列模型的一次重要升级。在现有版本的基础上,小米正积极推进该模型在计算效率方面的优化,目标是在终端设备上实现离线部署,同时增强对用户自然语言指令的支持,进一步拓展声音编辑功能的全面性。这一进展不仅体现了小米在人工智能与音频处理领域的持续投入,也为未来更多智能化应用场景提供了技术支撑。
附 MiDashengLM 开源地址:
GitHub 主页:https://github.com/xiaomi-research/dasheng-lm
技术报告:https://github.com/xiaomi-research/dasheng-lm/tree/main/technical_report
模型参数(Hugging Face):https://huggingface.co/mispeech/midashenglm-7b
模型参数(魔搭社区):https://modelscope.cn/models/midasheng/midashenglm-7b
网页 Demo: https://xiaomi-research.github.io/dasheng-lm
交互 Demo:https://huggingface.co/spaces/mispeech/MiDashengLM
人工智能最新资讯

2025-08-04 15:56:43
2025-08-04 15:49:26
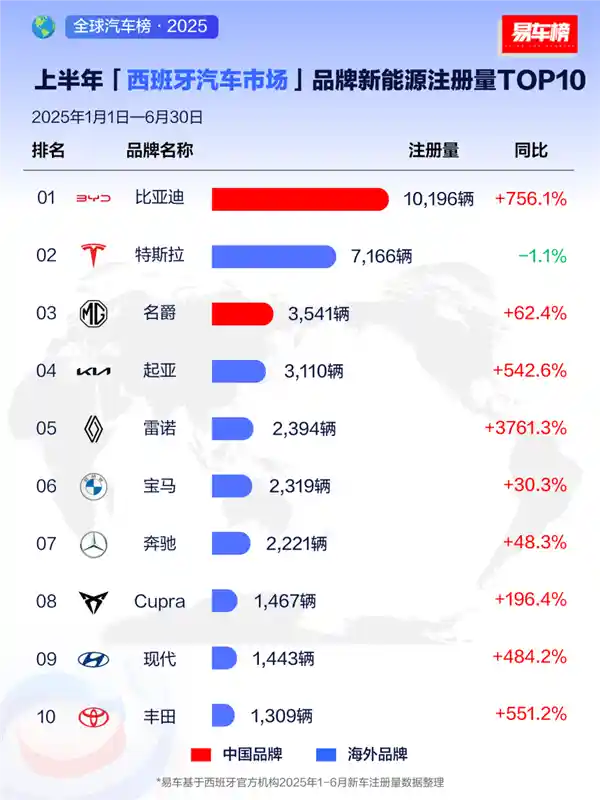
2025-08-04 15:36:51

2025-08-04 15:35:41

2025-08-04 15:34:15
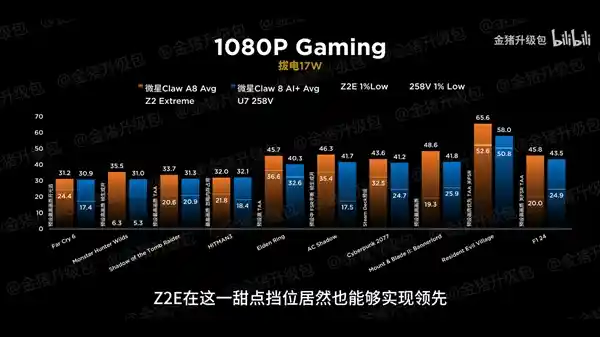
2025-08-04 15:33:03

2025-08-04 15:28:40

2025-08-04 15:25:10

2025-08-04 15:24:56

2025-08-04 15:16:19

2025-08-04 15:12:44
2025-08-04 15:11:41

2025-08-04 15:10:37

2025-08-04 15:10:13

2025-08-04 15:04:23
2025-08-04 15:03:13

2025-08-04 15:02:05

2025-08-04 15:00:04

2025-08-04 14:59:38

2025-08-04 14:57:57

2025-08-04 14:55:16

2025-08-04 14:53:07

2025-08-04 14:50:06

2025-08-04 14:49:51