OpenAI CEO突破认知:DeepSeek惊艳亮相,或将开源释放力量
「人工智能新里程碑:OpenAI CEO推出DeepSeek,引爆开源革命!」
北京时间2月1日凌晨,为应对DeepSeek-R1带来的挑战,OpenAI正式发布了o3-mini模型。这是OpenAI推理系列中的最新成员,也是目前最具成本效益的模型,并已开始在ChatGPT和API中提供使用。 这个新发布的o3-mini模型无疑给市场带来了新的活力。它不仅展示了OpenAI强大的研发能力,还体现了其在面对竞争对手时迅速做出反应的决心。随着人工智能技术的快速发展,各大科技公司之间的竞争愈发激烈。这次OpenAI推出的o3-mini模型,不仅增强了自身的竞争力,也为用户提供了更多选择,这无疑是一个双赢的局面。希望未来能有更多这样的创新成果,推动整个行业向前发展。

据悉,该模型在数学代码等基准测试中取得了显著的突破,刷新了现有的最先进水平(SOTA)。特别是在o3-mini(high)版本中,其在准确率和校准误差(CalibrationError)方面表现尤为出色,成为同类测试中的佼佼者。这一成就不仅展示了技术团队在算法优化上的卓越能力,也预示着未来在人工智能领域内可能实现更多创新与进步。

△o3-mini与o1在AIME竞赛数学的得分对比

据介绍,o3-mini的价格比OpenAI o1-mini便宜63%,比满血版o1便宜93%。开发者可以根据需要选择高、中、低三种推理强度,使o3-mini在应对复杂问题时能够进行深入分析,从而在速度和精确性之间找到最佳平衡。
具体来说,目前,ChatGPT为免费用户提供了一个名为o3-mini的版本,该版本具有一定的速率限制,类似于现有的GPT-4o限制。Plus用户则可以选择更为智能的o3-mini-high版本。而每月支付200美元的Pro用户则可以无限制地使用o3-mini和o3-mini-high。 这样的分层服务模式能够满足不同用户的需求,既能让普通用户在有限的条件下体验到先进的AI技术,也确保了付费用户可以获得更加优质的服务。对于希望获得更高级别智能支持的专业人士而言,这种付费升级的机制无疑是一个吸引人的选项。同时,这也体现了技术公司通过差异化服务来平衡成本与用户体验的一种策略。
API层面,o3-mini的输入价格为1.10美元/百万token,输出价格为4.40美元/百万token,相比o1-mini便宜了63%,相比满血版o1便宜了93%,但仍然是GPT-4omini的约7倍价格。
OpenAI宣布,o3-mini的推出是其在高效能智能技术领域的一个重要进展。通过提升科学、技术、工程和数学方面的推理能力,并且控制在较低成本内,使得高质量的人工智能技术更加普及易得。
在未来几周,满血版的o3将正式上线,这是继o3-mini发布之后的一个重要进展。OpenAI的联合创始人兼首席执行官山姆·奥尔特曼在最近的一次在线问答活动中透露了这一消息。 从我个人的角度来看,这无疑是一个令人兴奋的消息。随着满血版o3的推出,我们有理由期待其性能将比mini版本有显著提升。这不仅展示了技术的进步,也表明了公司在持续创新和优化产品方面的承诺。对于科技爱好者和行业观察者来说,这将是值得关注的重要时刻。
谈及对DeepSeek的看法,奥尔特曼表示:“它(DeepSeek)确实是一个非常出色的模型,OpenAI将会研发出更为先进的模型,但我们的领先优势可能不会再像过去那样明显了。”
奥尔特曼罕见地公开承认了团队的失误,并透露OpenAI正在考虑采用一种新的开源策略。这一表态不仅展现了公司在面对挑战时的透明度和自我反省能力,也反映了技术行业在发展过程中对开源文化的重视与重新评估。这种开放的态度有助于增强公众对AI技术的信任,并推动相关领域的进一步创新与发展。 修改后的版本: 奥尔特曼罕见地公开承认了自己的错误,并表示OpenAI正在探讨一种新的开源策略。这样的坦诚不仅体现了公司在面对挑战时的透明度和自我反思能力,同时也显示了技术行业对开源文化态度的变化与再思考。这种积极的姿态有望加强公众对人工智能技术的信心,并促进该领域内的持续进步与创新。
我认为在这个问题上我们的立场可能有误,需要制定一项不同的开源策略;并非OpenAI的所有成员都认同这一看法,而且这目前并不是我们的首要任务。
值得一提的是,图灵奖得主、负责Meta AI研究的首席科学家Yann LeCun近日表示,DeepSeek取得成功的重要收获在于,AI开源的价值使得每个人都能从中获益。
“对于那些看到DeepSeek的表现后认为‘中国在人工智能领域正超越美国’的观点,我认为正确的解读应该是‘开源模型正在逐渐超越专有模型’。DeepSeek从开放的研究和开源项目中获得了巨大的助力,就像PyTorch和Llama一样。他们不仅提出了新的想法,还在此基础上进行创新。他们发布的新模型也是开源的,使得每个人都可以从中受益。这正是开放研究和开源精神的力量。” 这种现象表明,开源模式正在推动全球人工智能技术的发展,而不仅仅是某个国家或企业的竞争。开源模式让更多的研究人员和开发者能够参与到技术创新中来,从而加速了整个领域的进步。这不仅促进了知识和技术的共享,也为更多人提供了参与的机会,有助于构建一个更加公平和开放的技术生态系统。
近期,中国AI技术厂商DeepSeek近期推出的V3和R1两款开源AI模型,在业界引发了巨大反响。这两款模型不仅在性能上表现出色,而且在算力需求方面也展现了令人瞩目的优势,彻底改变了人们对于“AI算力需求”的传统认知。这表明,随着技术的进步,未来AI的应用将更加广泛和高效,同时也为其他研发团队提供了新的思路和方向。
特别是DeepSeek推出的推理大模型DeepSeek-R1,其不仅性能比肩OpenAI o1 ,并且其所需的训练成本可能只有后者的约1/20(仅用了2048 个 H800 GPU,花了两个月的时间训练完成,仅花费了约558万美元),API的定价更是只有后者的约1/28,相当于使用成本降低了约97%。
也就是说,DeepSeek使用了非顶尖的AI芯片,通过较低的算力需求和更低的成本,实现了与OpenAI等美国领先AI技术公司顶级大型模型相媲美的效果。
这一成就被视作对美国在人工智能领域的领导地位构成挑战,不仅让OpenAI、Meta、谷歌等多家大型模型公司感到恐慌,还导致英伟达等AI芯片企业的市值重新评估和股价大幅下跌。
然而,据SemiAnalysis报道,外界普遍认为DeepSeek公司拥有5万张H100 GPU计算卡,但该机构指出,DeepSeek实际囤积了6万张英伟达GPU卡,其中包括1万张A100、1万张H100、1万张“定制版”H800和3万张“定制版”H20。按照总体拥有成本(TCO)计算,其算力资本支出超过了140亿元,即19.96亿美元(约合人民币143.45亿元)。
DeepSeek的全部服务器投资总额约为16.29亿美元,而运维这些服务器集群的费用高达9.44亿美元,因此总的投入成本可能达到25.73亿美元。
但是,DeepSeek尚未进行过大规模融资,其背后的母公司幻方也似乎不太可能做出如此大规模的硬件投资。 这一情况反映了当前科技创业公司在资金筹集方面的现实困境。尽管DeepSeek及其母公司幻方在技术领域可能具备一定的创新力,但面对高昂的研发成本和激烈的市场竞争,他们仍然需要谨慎管理财务资源。这也提示我们,在评估一家公司的发展潜力时,除了关注其技术和产品本身,还应考虑其财务状况和融资能力。
根据DeepSeek官方公布的数据,其DeepSeek-V3的训练仅使用了大约2080块英伟达H800加速卡,这部分的芯片投资约为4000万美元左右。
而且,DeepSeek在训练其AI模型时,并不一定需要拥有庞大的自有硬件基础设施,完全可以借助第三方资源来进行大模型的训练。这种做法不仅能够节省大量的前期投入,还能更加灵活地根据项目需求调整资源规模,从而提高效率和降低成本。 这样的策略显示了DeepSeek在资源配置上的灵活性和前瞻性,通过利用外部的高性能计算资源,可以更高效地推进技术研发,同时也减少了企业自身的运营风险。这为其他初创企业和研究机构提供了一个很好的范例,即如何在有限的资源条件下实现技术突破和发展。
不过,如果SemiAnalysis关于DeepSeek囤积了6万块英伟达GPU加速卡的分析准确无误,那么这意味着DeepSeek当前拥有的AI硬件资源已经足够支持其在未来沿着现有技术路线持续开发出多代性能更加强大的AI大模型。
人工智能最新资讯

2025-08-04 15:56:43
2025-08-04 15:49:26
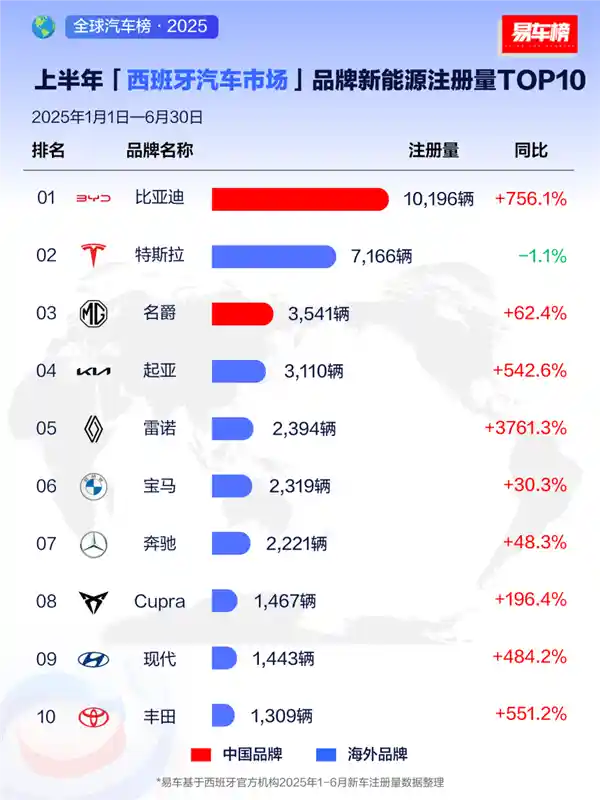
2025-08-04 15:36:51

2025-08-04 15:35:41

2025-08-04 15:34:15
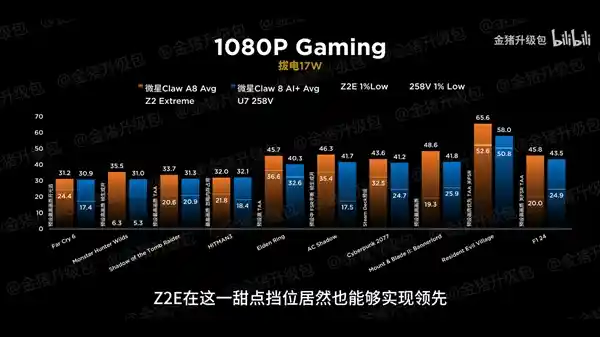
2025-08-04 15:33:03

2025-08-04 15:28:40

2025-08-04 15:25:10

2025-08-04 15:24:56

2025-08-04 15:16:19

2025-08-04 15:12:44
2025-08-04 15:11:41

2025-08-04 15:10:37

2025-08-04 15:10:13

2025-08-04 15:04:23
2025-08-04 15:03:13

2025-08-04 15:02:05

2025-08-04 15:00:04

2025-08-04 14:59:38

2025-08-04 14:57:57

2025-08-04 14:55:16

2025-08-04 14:53:07

2025-08-04 14:50:06

2025-08-04 14:49:51