「字节跳动引领新潮:OmniHuman 多模态框架震撼登场,图片与音频完美融合,创造逼真动画效果」
「数字革命再进化:OmniHuman 多模态框架颠覆传统,领跑动画科技新时代」
2月6日的消息,字节跳动的研究团队最近展示了一项AI技术,该技术能够利用一张图片和一段音频生成半身或全身的视频。
字节跳动指出,与其他仅能制作面部或上半身动画的深度伪造技术有所区别,OmniHuman-1可以生成更为真实的全身动画,并且能够准确地将手势、面部表情与语音或音乐同步。
字节跳动在其OmniHuman-lab项目网页上发布了多段测试视频,其中包括由AI生成的TED演讲以及一段仿佛是阿尔伯特·爱因斯坦在讲话的视频。
在周一发布的一篇论文中,字节跳动指出,OmniHuman-1 模型支持不同的体型和画面比例,从而使视频效果更自然。
据了解,字节跳动宣布,OmniHuman-1模型是在大约19000小时的人类运动数据基础上进行训练的,这使得它不仅能在内存限制内生成任意长度的视频,还能适应各种不同的输入信号。 这项技术突破无疑为人工智能在视频生成领域的应用开辟了新的道路。通过如此庞大的数据集训练出的模型,OmniHuman-1不仅能够模拟人类动作的多样性,还可能在影视制作、虚拟现实以及在线教育等多个领域发挥重要作用。然而,随着技术的进步,如何确保这些模型不会被滥用,成为了一个需要全社会共同关注的问题。
研究人员指出,OmniHuman-1在真实性和准确性上表现卓越,超过了现有的其他同类动画工具。目前,该工具尚未对外开放下载或相关服务。 从行业发展的角度来看,OmniHuman-1的推出无疑是一个重要的里程碑,它不仅展示了技术的进步,也为未来的动画创作提供了新的可能性。不过,对于广大开发者和爱好者而言,暂时无法获取这一工具可能会带来一定的遗憾。希望未来能有更多机会接触到这样的先进技术,以便推动整个行业的进一步发展。
人工智能最新资讯

2025-08-04 15:56:43
2025-08-04 15:49:26
2025-08-04 15:36:51

2025-08-04 15:35:41

2025-08-04 15:34:15
2025-08-04 15:33:03

2025-08-04 15:28:40

2025-08-04 15:25:10

2025-08-04 15:24:56

2025-08-04 15:16:19

2025-08-04 15:12:44
2025-08-04 15:11:41

2025-08-04 15:10:37

2025-08-04 15:10:13

2025-08-04 15:04:23
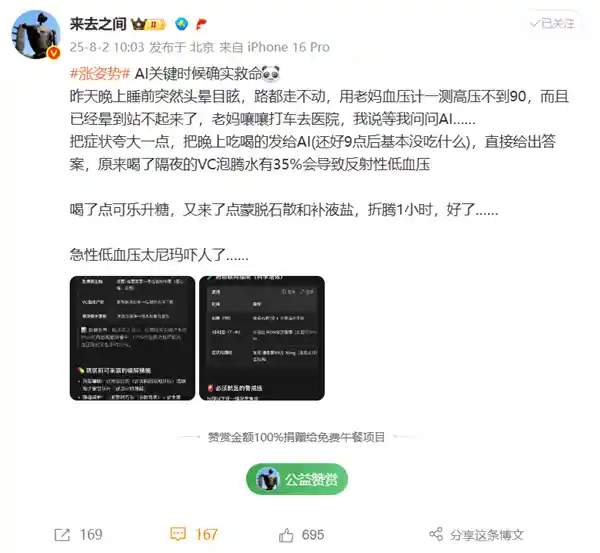
2025-08-04 15:03:13

2025-08-04 15:02:05

2025-08-04 15:00:04

2025-08-04 14:59:38

2025-08-04 14:57:57

2025-08-04 14:55:16

2025-08-04 14:53:07

2025-08-04 14:50:06

2025-08-04 14:49:51