黑客利用恶意 AI 模型,巧妙规避监测:通过损坏pickle文件实施攻击
AI黑客:玩坏pickle文件,玩转监测漏洞
2月10日消息,据TheHackerNews于8日报道,网络安全专家发现,在HuggingFace平台上,存在两个恶意机器学习(ML)模型采用了非传统的“损坏”pickle文件技术以避开安全检测。
ReversingLabs的研究员Karlo Zanki指出:“从这些PyTorch存档中解压出的pickle文件在开头就暴露了恶意的Python代码。这两种恶意负载均属于典型的针对特定平台的反向Shell,且连接到了预设的IP地址。”
这种方法名为nullifAI,旨在巧妙地规避现有的安全防护机制,从而避免被识别为恶意模型。最近,在HuggingFace平台上发现了两个与之相关的模型存储库。 这种技术手段引发了广泛的讨论。一方面,它展示了人工智能领域某些技术的潜力和灵活性,但另一方面,这也暴露出当前安全系统可能存在的漏洞。开发者们需要更加警觉,不断更新和完善防护措施,以确保人工智能系统的安全性。同时,这也提醒我们,随着技术的发展,我们需要制定更完善的法律法规来规范此类技术的应用,以防止其被用于不正当的目的。
glockr1/ballr7
who-r-u0000/0000000000000000000000000000000000000
这些模型更像是一种概念验证(PoC),而不是实际的供应链攻击事件。
pickle序列化格式在机器学习模型的分发过程中非常普遍,但其一直被视为存在安全风险,因为在加载和反序列化时可能会执行任意代码。
被检测出的这两个模型采用的是PyTorch格式,实际上是经过压缩的pickle文件。尽管PyTorch通常使用ZIP格式进行压缩,但这些模型使用的是7z格式。这种不同的压缩方法使它们能够规避HuggingFace的Picklescan工具的恶意检测。 请注意,这些模型在本质上仍然是PyTorch格式的,只是采用了更为隐蔽的压缩方式。这使得检测变得更加困难,但也引发了对于模型安全性的关注。
Zanki进一步表示:“这个pickle文件的一个有趣之处在于,对象序列化(注:即pickle文件的核心功能)在执行恶意负载之后便中断,从而无法正确地反序列化对象。”
后续分析显示,即使存在反序列化错误,受损的pickle文件依然可以被部分反序列化,进而执行恶意代码。此问题已经得到解决,Picklescan工具也进行了版本更新。
Zanki解释说:“pickle文件的反序列化过程是逐步进行的,每个pickle操作码都会在遇到时立即执行,直至所有操作码被执行完毕或者遇到损坏的指令。由于恶意载荷被放置在pickle流的起始位置,这使得HuggingFace的安全扫描工具在检测模型执行风险时存在盲点。” 这种设计上的漏洞确实令人担忧。虽然pickle模块提供了强大的序列化功能,但其默认的反序列化机制却为潜在的攻击者敞开了大门。对于依赖pickle处理敏感数据的应用来说,必须采取额外的安全措施来防止此类风险,例如使用更安全的替代方案或对输入进行严格的验证。此外,开发人员应更加关注代码库中的安全盲区,并及时更新相关安全策略,以应对不断变化的安全威胁。
人工智能最新资讯

2025-08-07 12:23:28

2025-08-07 11:52:33

2025-08-07 11:48:09

2025-08-07 11:29:18

2025-08-07 10:50:12

2025-08-07 10:48:22
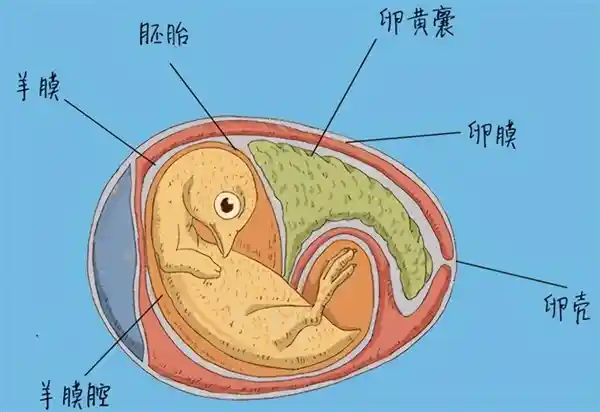
2025-08-07 10:44:06

2025-08-07 10:25:55
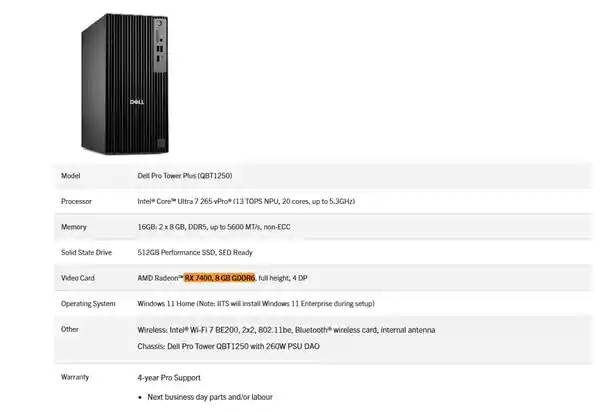
2025-08-07 10:23:09
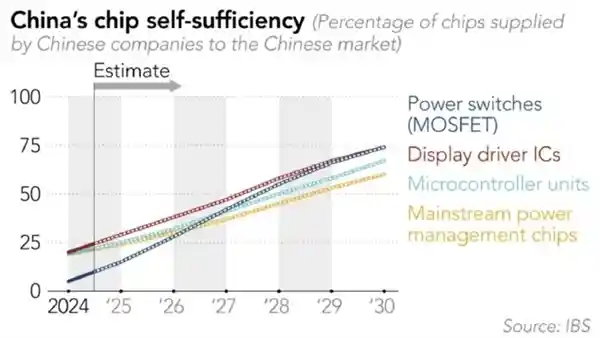
2025-08-07 10:20:44

2025-08-07 10:18:25

2025-08-07 10:16:45

2025-08-07 10:16:18

2025-08-07 10:15:44

2025-08-07 10:13:39
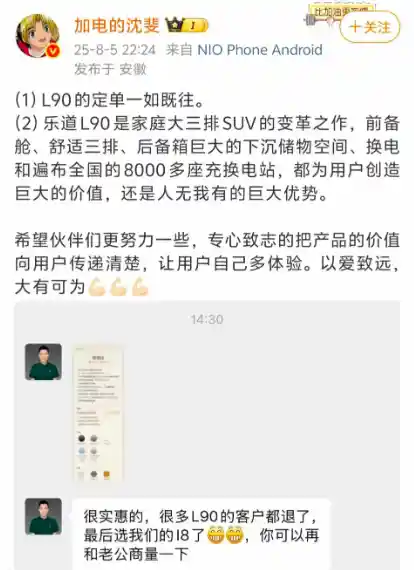
2025-08-07 10:13:24
2025-08-07 10:10:40

2025-08-07 10:10:22

2025-08-07 10:05:35

2025-08-07 10:01:20

2025-08-07 09:58:44

2025-08-04 15:56:43
2025-08-04 15:49:26
2025-08-04 15:36:51
