魔刃黑金之美:影驰GeForce RTX 5080魔刃显卡全面评测【DLSS 4.0 全新升级】
风暴来袭:全面解析影驰GeForce RTX 5080魔刃显卡,DLSS 4.0全新升级震撼登场!
英伟达基于Blackwell架构打造的GeForce RTX 50系列游戏显卡一经发布,迅速在硬件市场掀起波澜,各大硬件厂商纷纷跟进,推出自家的RTX 50系列显卡。今天,我们将目光投向影驰GeForce RTX 5080魔刃显卡。这款显卡定位RTX 50系列中的中高端市场,凭借全新的Blackwell架构,融合DLSS 4技术与第五代Tensor Core,实现了游戏性能与AI计算能力的全面提升。无论是畅玩那些画面精美的3A游戏大作,还是投身于复杂的创意设计工作,它都能凭借强劲的性能表现,为用户带来出色的体验。接下来,我们将深入挖掘,从性能释放、散热效能、外观设计等多个维度,为大家详细剖析这款显卡的真实实力。 如今,时间来到2025年02月10日,我们再次审视影驰GeForce RTX 5080魔刃显卡。该显卡自发布以来,一直备受关注,不仅因为其采用了先进的Blackwell架构,还因为它集成了DLSS 4技术和第五代Tensor Core。这些技术的结合,使得这款显卡在游戏性能和AI计算方面都取得了显著的进步。无论是面对最新款的3A游戏大作,还是应对繁重的创意设计任务,这款显卡都能展现出色的表现。接下来,我们将从性能释放、散热效能以及外观设计等方面,为大家详细解析这款显卡的实际性能。
为了充分利用显卡的强大性能,此次的测试平台配置如下:
影驰GeForce RTX 5080 魔刃显卡的设计风格简洁而硬朗,以黑金为主色调,配合硬朗的线条和锐利的散热鳍片,展现出一种独特的工业美感。这款显卡不仅在视觉上给人留下深刻印象,而且其设计也充分考虑了散热性能,确保长时间游戏或工作时能够稳定运行。 这种设计风格既体现了现代科技产品的简洁美学,又不失为对高性能需求的一种回应。黑金配色不仅显得高端大气,还易于与各种机箱内部装饰相匹配,适合追求个性化装机的玩家。整体来看,影驰GeForce RTX 5080 魔刃显卡在美观与实用之间找到了一个很好的平衡点。
显卡正面配备了三枚黑色环形刀锋风扇,这些风扇在中心位置设计了一个高光Logo,在不同光线照射下,Logo会呈现出丰富的光泽变化,显得非常有高端质感。金属装甲采用了低饱和度的黑色调,并巧妙地加入了金色元素作为点缀,精细的布局和纹理设计不仅提升了整体的层次感,也赋予了产品一种独特的视觉冲击力。 这样的设计既保证了设备的散热性能,又不失时尚感,对于追求高性能和高颜值的用户来说,无疑是一个很好的选择。同时,这种细节上的精致处理也体现了制造商对产品质量和用户体验的重视。
尺寸方面,影驰GeForce RTX 5080 魔刃显卡的尺寸为358mm x 111.7mm x 49.7mm(不包括挡片),重量约为1.4kg。
显卡背板采用了硬朗的工业风格设计,右侧的大面积斜切矩形开孔十分引人注目,提升了整体的视觉效果。从这些开孔望进去,可以观察到内部复杂的散热结构,结合均热板和镀镍复合热管,运用了贯穿式的散热方案,以达到最佳的散热性能。
显卡两面装备了坚固的散热护甲,靠近背板的部分还加入了一条金色强化条。顶部侧面设有凹刻字符的“GEFORCERTX”标识。
居中位置为 16 - pin 显卡供电接口。
I/O 接口方面,显卡提供 3 个 DP2.1b 接口以及 1 个 HDMI 接口,整体设计简洁大方,兼具功能性与美观性。
NVIDIA 新推出的 GeForce RTX 5080 显卡,搭载了具有革命性的 Blackwell 架构。该架构深度融合 AI 运算单元与图形管线,打破了传统渲染技术的物理限制。其创新性地构建神经网络渲染体系,使单帧画面生成效率比传统方式提升了 400%,成功攻克了画面品质与帧率同步提升的技术难题。
在计算架构方面,Blackwell采用了第五代混合精度计算技术。这一代的TensorCore支持FP4自适应量化,通过智能的数据压缩算法,显著降低了显存占用达56%,同时保持了模型的计算精度,使得AI推理速度翻了一番。实际测试表明,在处理如StableDiffusionXL这样的AI图像生成任务时,Blackwell架构下的处理时间仅需Ada架构所需时间的38%左右,这无疑大幅提高了工作效率。 这种技术进步不仅展现了硬件设计与软件优化结合的巨大潜力,也为AI领域的应用带来了革命性的变化。特别是对于需要大量计算资源的图像生成任务而言,Blackwell架构不仅能提供更快的处理速度,还能有效减少资源消耗,这对于推动AI技术的广泛应用具有重要意义。此外,随着这种高效能架构的普及,预计未来会有更多的创新应用涌现出来,进一步促进人工智能技术的发展。
光线追踪性能显著增强。重构后的 RT Core 采用并行光线 - 几何体交叉检测机制,三角形相交检测速度达到初代 Turing 架构的 8 倍。搭配新型 BVH 压缩算法,显存带宽占用减少 25%,单场景实时渲染多边形数量超 50 亿。在《赛博朋克 2077》全极致设定下,路径追踪帧率比 RTX 4080 提升 170%,带来更逼真的光影效果和流畅的游戏体验。
存储子系统升级到了GDDR7标准,采用了PAM3三重脉冲调制技术,每个时钟周期可以传输1.5比特的数据,在28Gbps的基础速率下实现了672GB/s的显存带宽,相比GDDR6X功耗降低了18%。结合PCIe 5.0 x16接口以及第四代NVIDIA显存压缩技术,4K纹理加载速度达到了毫秒级响应。 这种技术进步无疑为高性能计算和图形处理领域带来了显著的性能提升。通过引入GDDR7标准,不仅在带宽上实现了质的飞跃,同时还在能效方面取得了突破,这对于追求高性能计算设备的用户来说无疑是个好消息。此外,借助PCIe 5.0 x16接口和先进的显存压缩技术,使得在高分辨率下的图像处理速度得到了极大的优化,这将极大提升游戏和专业应用中的用户体验。
Blackwell 架构的革新,标志着图形处理器迈入智能渲染时代。通过将 AI 运算深度嵌入图形管线,让 8K 全景光线追踪等曾受摩尔定律限制的技术得以应用。NVIDIA 官方数据显示,在 3DMark Speed Way 测试中,Blackwell 架构性能较前代提升 215%,AI 加速效能提升更是高达 570%。
影驰GeForce RTX 5080 魔刃显卡采用了最新的GB203-400-A1核心,基于TSMC 4N工艺。该显卡配备了10752个CUDA核心、336个Tensor核心、84个光追核心、336个纹理单元和128个ROP单元。相较于RTX 4080,它的核心规模提升了大约10.5%,同时在SM(流式多处理器)和TPC(纹理处理集群)的数量上也有所增加。显存方面,从GDDR6升级到了256-bit 16GB GDDR7,带宽高达960GB/s。TGP功耗为360W,较上一代RTX 4080增加了40W。 这款显卡的性能提升明显,特别是在光线追踪和AI计算能力方面,这无疑将为游戏和专业应用带来更流畅的体验。然而,功耗的增加也需要用户在电源配置上做出相应的调整,以确保系统稳定运行。总体来看,影驰RTX 5080魔刃显卡在性能和功能上的增强使其成为市场上值得关注的产品。
接下来我们将进行理论测试部分。影驰GeForce RTX 5080 魔刃显卡定位为中高端级别,测试前需要先介绍一款名为Xtreme Tuner的软件。这是一款专为NVIDIA显卡设计的超频和系统监控工具。借助此软件,用户能够调节显卡的核心电压、GPU频率以及显存频率等参数,从而达到优化显卡性能的目的。
先看烤机,单烤甜甜圈10分钟后,GPU核心温度维持在约68.8℃,显卡频率为2527MHz,功耗稳定在360W左右,与公版规格相符。
在3DMark Time Spy DX12测试中,影驰GeForce RTX 5080魔刃显卡的表现令人印象深刻,得分达到了31499分,几乎与公版显卡的32022分持平。相比之下,上一代的GeForce RTX 4080公版显卡得分为29220分,性能提升了大约8%。这样的成绩不仅展示了影驰在非公版显卡上的技术实力,也体现了新一代显卡在性能上的显著进步。 这一结果显示,消费者在选择非公版显卡时,除了考虑品牌和设计外,还可以期待获得接近甚至超越公版显卡的性能表现。对于追求极致游戏体验和技术爱好者来说,这无疑是一个好消息。
在3DMark Time Spy Extreme DX12测试中,影驰GeForce RTX 5080魔刃显卡获得了15745分的成绩,相比之下,RTX 4080公版的分数为14541分,提升幅度大约为8%。
在3DMark Portal Royal 实时光追测试中,影驰 GeForce RTX 5080 魔刃显卡的综合分为21688分,相比之下,RTX 5080 公版的分数为22060分,而RTX 4080 公版的分数为18439分,提升幅度达到了18%。
根据对一系列3DMark测试的结果分析,影驰GeForce RTX 5080魔刃显卡相比上一代RTX 4080,在各项测试中的表现提升了大约8%到18%。这一数据表明,新一代显卡在性能上确实有了显著的进步。尽管提升幅度看起来并不算特别巨大,但考虑到当前显卡技术已经相当成熟,这样的进步仍然值得肯定。这不仅意味着游戏体验会有明显的改善,也预示着未来在图形处理和计算能力方面还有更大的潜力可挖。对于追求极致性能的游戏玩家和专业人士来说,这无疑是一个令人振奋的消息。
在游戏测试环节,尽管 NVIDIA 官方称首批支持 DLSS 4 的游戏多达 75 款,但鉴于当前能顺畅开启 DLSS 4 相关选项的游戏寥寥无几,因此对于多数主流游戏,我们仍测试 DLSS 3 和帧生成的表现,仅通过《赛博朋克:2077》与《心灵杀手 2》这两款游戏,单独展示 DLSS 4 技术的实际效果。
1、《CS2》
首先是《CS2》,在更新升级后性能要求显著提升的《CS2》中,影驰GeForce RTX 5080魔刃显卡在4K分辨率和高画质设置下跑出了280帧的游戏平均帧数,1%Low帧也达到了120帧。
而在 2K 分辨率 + 高画质下则跑到了平均 455 帧的游戏帧数,1% Low 帧提升到 203 帧,游戏过程中丝毫不会影响发挥。
2、《古墓丽影:暗影》
传统光栅单机游戏可以考察一下 RTX 5080 在非光追和 DLSS 时的性能表现:
在 4K 分辨率 + 最高画质下,游戏平均帧数为 142 帧;
在 2K 分辨率 + 最高画质下,游戏平均帧数为 225 帧;
3、《极限竞速:地平线 5》
《极限竞速:地平线 5》有着较为出色的优化:
在 4K 分辨率 + 极端画质下,游戏平均帧数为 145 帧;
在 2K 分辨率 + 极端画质下,游戏平均帧数为 196 帧;
相比公版 RTX 4080s,4K 和 2K 分辨率下的游戏平均帧数提升分别达到了 20% 和 38%。4、《孤岛惊魂 6》
接下来就是光追游戏了,首先是《孤岛惊魂 6》,它对 CPU 的单核性能要求也很高,支持光追和 DLSS。经过实测:
在 4K 分辨率 + 极高画质下,游戏平均帧数为 155 帧,1% Low 帧 120 帧;
在 4K 分辨率 + 极高画质 + 开启光追 + DLSS 质量下,游戏平均帧数为 128 帧,1% Low 帧 55 帧;
在 2K 分辨率 + 极高画质下,游戏平均帧数为 193 帧,1% Low 帧 53 帧;
在2K分辨率和极高画质设置下开启光追和DLSS质量模式时,游戏的平均帧数达到148帧,而1%Low帧数则为50帧。
5、《黑神话:悟空》
接下来就是显卡测试绕不开的“众生平等”之作《黑神话:悟空》了:
4K 分辨率 + 影视级画质 + 50% 超采样分辨率 + 高全景光追,游戏平均帧数为 68 帧;
在4K分辨率和影视级画质条件下,启用50%超采样分辨率并关闭全景光追帧生成功能时,游戏的平均帧数为80帧。
而切换到 2K 分辨率后:
在2K分辨率影视级画质50%超采样分辨率条件下,游戏的平均帧数达到了86帧。
在2K分辨率影视级画质50%超采样分辨率高全景光追帧生成下,游戏平均帧数为101帧。这样的性能表现依然十分出色,未来《黑神话:悟空》也将支持DLSS4,到时对游戏体验的改进,无疑会更加令人期待。
上一代的RTX 40系列已经支持了强大的DLSS3技术,而DLSS4在此基础上更进一步,深入挖掘帧生成的性能潜力。它采用全新的多帧生成技术,依托于第五代张量核心的强大性能,通过AI算法为每个渲染帧最多生成三个额外帧,从而显著提高游戏的FPS。
DLSS 4 可与光线重建、超分辨率、DLAA 等 DLSS 技术协同运作,最高能让游戏帧率提升至传统渲染方式的 8 倍。玩家在游戏中启用 DLSS 4 并搭配 RTX 5080 显卡,便能轻松畅享开启全景光线追踪的 4K 高帧率游戏体验。
NVIDIA GeForce RTX 50 系列配备的第五代 Tensor Core 在 AI 处理性能上实现了显著提升,相比前代产品提升了 2.5 倍,大幅减少了游戏中的延迟现象。未来我们将会通过具体的游戏测试来展示这一变化。此外,Blackwell 架构的显示引擎对 DLSS 4 技术提供了强有力的支持,它通过增强像素处理能力,使得 DLSS 4 能够更好地应对高分辨率和高刷新率的需求,最高可以将像素处理能力提升一倍。
DLSS 4 技术在模型架构上的革新令人瞩目。这项技术结合了 DLSS 光线重建、DLSS 超分辨率以及 DLAA 等功能,并由首个实时 Transformer 模型推动。该模型运用自注意力机制,能够评估每一帧或多个帧中每个像素的重要程度,从而更准确地解析场景内的复杂关系。这样的设计不仅增强了生成像素的稳定性,减少了伪影现象,同时在处理运动细节和边缘方面表现出色,使得画面更加流畅自然。 从这一进展可以看出,英伟达在图像处理技术上的突破已经达到了新的高度。DLSS 4 不仅提升了游戏体验,还为专业领域如视频编辑和动画制作带来了巨大的潜力。随着技术的不断进步,未来我们有理由期待更高质量的视觉效果和更流畅的游戏性能。
《赛博朋克:在2077的Steam测试版中,已经可以看到DLSS 4的身影。据观察,在4K分辨率和超级画质设置下,如果不开启光线追踪和DLSS技术,游戏的平均帧数可以稳定在70.86帧。这项技术无疑为玩家提供了更为流畅的游戏体验,尤其是在高分辨率和高画质需求的情况下。DLSS 4的引入不仅提升了游戏性能,还减少了硬件负担,使得更多玩家能够享受到接近原生画质的视觉效果。对于追求极致画面与流畅度的玩家来说,DLSS 4无疑是一个值得期待的技术革新。
打开帧生成选项后,可以看到下面多出了一个多帧生成的倍率选择项,即 DLSS Multi Frame Generation,可选择包括 3x 和 4x 在内的生成倍率。
我们在4K分辨率、超级光追画质及DLSS性能设置下,分别选择了3x和4x多帧生成进行游戏基准测试,结果得到的平均帧数分别为195.71帧和241.89帧。3x多帧生成的表现几乎等同于70.86帧的三倍,而在4K分辨率下超过240帧的超级光追画质体验远远超出了我们的预期,画面的流畅度极高。
在切换至超速光追画质并启用DLSS 4多帧生成技术后,这款游戏的平均帧数达到了142.81帧和181.15帧。这在一款对硬件性能要求极高的3A游戏中,确实令人惊讶。DLSS 4技术的引入不仅大幅提升了游戏性能,还彻底颠覆了我们对高性能游戏体验的传统认识。这项技术的发展,无疑为未来的游戏开发和硬件优化开辟了新的可能性,使得高画质与高帧率不再是难以兼得的奢望。
当然,无论哪种插帧方式,延迟的增加都是无法避免的。因此,我们实际测试了关闭和开启多帧生成后的延迟表现。在关闭帧生成选项的情况下,我们在4K超高光线追踪画质下进行游戏,平均延迟为33毫秒。在同一场景下分别开启3x和4x多帧生成,游戏平均延迟分别为44毫秒和49毫秒。
如此看来相比开启帧生成之前,延迟的确有一定的增加。不过 3x 和 4x 多帧生成延迟依次递增 3ms、5ms,总体延迟都控制在 50ms 以内,对于非竞技类单机游戏来说这个表现完全可以接受。
事实上,帧生成确实会提升一定的游戏延迟,好在对于《赛博朋克:2077》这款游戏来说,影响并不大。开启多帧生成后,总体延迟控制在 30ms 以内,实际游戏过程中,即便是射击和砍杀操作也不会出现延迟不跟手的情况。那接下来我们再来看看《心灵杀手 2》的表现。
在 4K 分辨率 + 原生最高画质下,游戏的平均帧数为 46 帧,注意此时游戏的延迟只有 57ms。
而一旦我们开启光追选项,游戏平均帧数立刻会跌到无法流畅游玩的水平:
在4K分辨率下开启原生最高画质和光线追踪功能时,某款游戏的表现显得有些吃力,平均帧数仅为24帧,而最低1%的帧数更是低至21帧。 这样的表现让不少追求极致视觉体验的玩家感到有些失望。尽管4K分辨率和光线追踪技术能带来令人震撼的视觉效果,但目前看来,对于显卡性能的要求依然很高。希望未来随着硬件技术的进步,游戏开发者能够更好地优化游戏,让更多的玩家能够在不牺牲画质的前提下享受到流畅的游戏体验。
4K 分辨率 + 原生最高画质 + 路径光追下,游戏平均帧数为 16 帧,1% LOW 帧 2 帧;
与此同时,大家应该也注意到开启光追后的游戏平均延迟会大幅提升,由原先的 57ms 提升到了 106ms 和 157ms,游戏体验已经无法保证。那么 DLSS 4 技术能扳回一局吗?
启动多帧生成功能后,战局随即得到了改观,使用3x和4x多帧生成模式下的游戏平均帧数分别达到了139帧和185帧,尽管不如《赛博朋克:2077》中的表现那么惊艳,但性能上的提升还是相当显著的。
而在游戏平均延迟的表现上,开启多帧生成后帧数相比 4K + 路径光追下少了一半,来到 56ms,3x 和 4x 多帧生成下的增幅和《赛博朋克:2077》保持一致,都是 5ms 左右的递增,毫无疑问 Reflax 低延迟功劳很大。考虑到《心灵杀手 2》刚刚适配 DLSS 4,目前的延迟表现可以接受,希望游戏后续能够进一步优化延迟表现。
说到延迟,为了解决目前DLSS4适配游戏较少的问题,英伟达推出了DLSS Override功能来缓解这一状况。该功能能够让那些已经支持DLSS但尚未进行DLSS4适配的游戏也能享受到DLSS4带来的帧生成和超分辨率体验。
我们以《漫威争锋》为例,在 4K 分辨率 + 高画质 + 关闭 DLSS 情况下,游戏平均帧数 181 帧,1% Low 帧 135 帧,游戏平均延迟 14ms;
在4K分辨率高画质DLSS质量档下,游戏的平均帧数为213帧,1%Low帧数为187帧,游戏平均延迟为15ms。
在相同的情境下,开启DLSSOverride并将DLSS 4帧生成设置为X4后,游戏平均帧数达到422帧,1%Low帧为291帧,游戏平均延迟为21毫秒。游戏帧率得到了显著提升,体验已与原生适配DLSS 4非常接近。
NVIDIA Reflex 2 作为新一代低延迟技术,在 DLSS 4 之外进一步提升游戏响应速度,优化操作手感。自推出以来,NVIDIA Reflex 已应用于超过 100 款游戏,有效降低 PC 延迟达 50%。Reflex 2 引入 Frame Warp 技术,同步鼠标输入与渲染帧,实现游戏帧的实时控制,提供定制化的低延迟体验。展望未来,NVIDIA Reflex 2 将为包括《无畏契约》在内的多款主流竞技和动作游戏提供支持,结合 DLSS 4 技术,打造更卓越的低延迟游戏表现。
生产力方面,实测了ULProcyon的图像编辑、视频剪辑和AI文本撰写等性能。在图像编辑方面,影驰GeForce RTX 5080魔刃显卡与AMDRYZEN9 9000X搭配获得了9629分,比公版RTX5080高出943分。
在视频剪辑性能测试中,得益于RTX5080基于Blackwell架构的第九代NVENC,其在H.264/H.265 4:2:2编码的8位和10位视频上表现出显著的优势。影驰GeForce RTX5080魔刃最终获得了63058分,比公版RTX5080高出425分。
最终的大型语言模型测试展示了AI性能的较量,面对拥有13B参数量的LLAMA2模型,平均OTS达到了83.91 tokens/s,相比公版RTX 3080的83.48 tokens/s有所提升。
经过对影驰GeForce RTX 5080魔刃显卡的评测,它以卓越的表现令人印象深刻。DLSS 4技术结合第五代Tensor Core,成为显卡的强大动力源。DLSS 4利用人工智能和先进科技,大幅提高游戏帧率,并优化了画质,使游戏体验更上一层楼。在实际游戏测试中,启用DLSS 4后,游戏流畅性明显增强,画面效果更为出色。
外观上,显卡采用了黑金色调,整体风格低调而硬朗。其线条刚劲有力,散热鳍片的设计锐利有型,配合风扇和金属装甲,展现出强烈的工业美学。背面独特的散热孔设计不仅美观,还显著提升了散热效率。这款显卡沿用了经典的黑金配色,对于偏好暗黑风格的玩家而言无疑是个不错的选择。无论是从游戏性能还是外观设计来看,影驰GeForce RTX 5080 魔刃显卡都表现出众,对游戏玩家和创作者来说,确实是一款极具吸引力的产品。 个人认为,这款显卡在设计上既注重了功能性又不失美感,尤其是在散热方面的创新设计,大大提升了产品的实用性和耐用性。此外,黑金配色不仅符合当前市场审美趋势,而且能够满足不同用户的个性化需求,相信会受到不少高端用户的青睐。
电脑硬件最新资讯

2025-06-18 13:30:17

2025-06-18 13:25:09
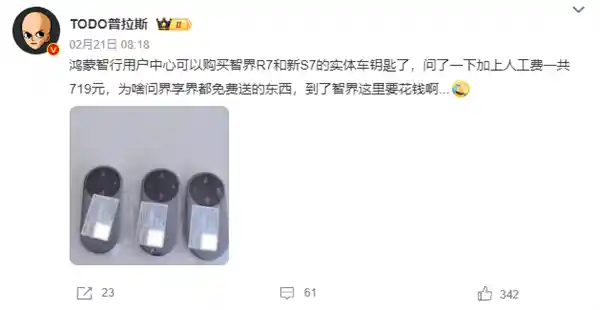
2025-06-18 13:19:20
![[vivo X Fold5首发第四代硅负极黑科技:6000mAh电量 薄过一元硬币 行业巅峰之作]](./www_images/20256/2025618/image_20250618131739342894.webp)
2025-06-18 13:17:43

2025-06-18 11:47:08

2025-06-18 11:46:00

2025-06-18 11:45:01

2025-06-18 11:40:13

2025-06-18 11:38:12

2025-06-18 11:34:08

2025-06-18 11:33:39

2025-06-18 11:29:15
2025-06-18 11:28:43

2025-06-18 11:27:24

2025-06-18 11:26:16

2025-06-18 10:59:11

2025-06-18 10:58:33

2025-06-18 10:49:35
![[TikTok入局日本电商市场,直播带货模式即将震撼上线]](./glo_kj_images_min/13.png)
2025-06-18 10:40:33
2025-06-18 09:46:55

2025-06-18 09:41:12
2025-06-18 09:36:45

2025-06-18 09:29:46
2025-06-18 09:19:57
