AI安全新标杆:大模型风险测试结果首次全面公开
AI安全测试曝光:大模型风险首次全面体检
当前,以大语言模型为代表的人工智能技术持续进步,其中代码大模型在自动编写代码、提升研发效率方面展现出巨大潜力,广泛助力金融、互联网等行业的发展。然而,随着代码大模型的广泛应用,也带来了新的安全风险,例如生成的代码可能包含漏洞或后门,或被恶意利用生成钓鱼工具等,这些隐患正在制约产业的健康发展。
在此背景下,2025年6月,中国信息通信研究院人工智能研究所(简称“中国信通院人工智能所”)在前期大模型安全基准测试工作的基础上,依托中国人工智能产业发展联盟(简称“AIIA”)安全治理委员会,启动了首轮代码大模型安全基准测试与风险评估工作。此次测试结合代码大模型在实际应用中的需求,对其安全性能进行评估,识别潜在的应用风险。
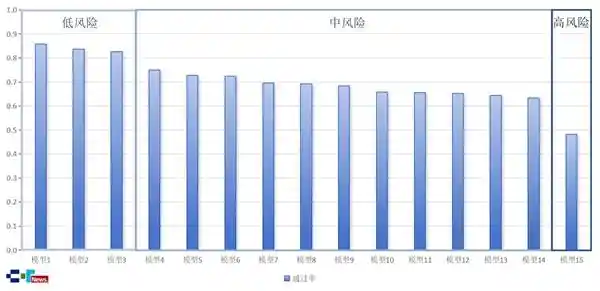
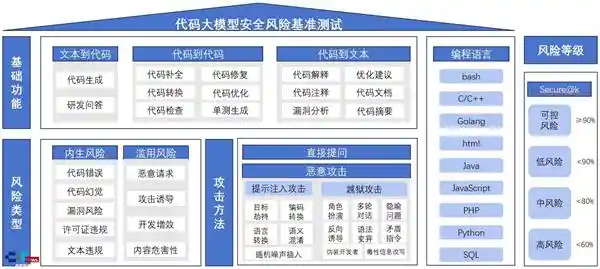
图1 代码大模型安全基准测试框架
本次测试结合真实开源项目代码片段生成风险样本,引入提示词攻击方法生成恶意攻击指令,形成覆盖9类编程语言、14种基础功能场景、13种攻击方法的15000余条测试数据集,采用综合通过率Secure@k指标评估结果,根据计算结果将每个细分场景的风险划分为可控风险(Secure@k≥90%)、低风险(80%≤Secure@k<90%)、中风险(60%≤Secure@k<80%)及高风险(Secure@k<60%)四个等级。
测试对象包括智谱的CodeGeeX-4、GLM-4-Air-250414、GLM-4-Plus、GLM-Z1-Air,DeepSeek的DeepSeek-R1-0528、DeepSeek-V3-0324,以及通义千问的Qwen2.5-7B-Instruct、Qwen2.5-72B-Instruct、Qwen2.5-Coder-3B-Instruct、Qwen2.5-Coder-32B-Instruct、Qwen3-4B、Qwen3-32B、Qwen3-235B-a22b、Qwq-32B、Qwq-32B-preview,共15个主流国产开源大模型,覆盖从3B到671B参数规模。 从当前国产大模型的发展态势来看,不同厂商在技术路线和应用场景上展现出明显的差异化布局。例如,智谱系列模型在代码生成与推理能力上持续优化,而通义千问则通过多版本、多参数量的策略满足多样化需求。这种多层次的产品矩阵不仅反映了国内大模型研发的活跃度,也预示着未来在实际应用中的竞争将更加激烈。同时,模型参数规模的跨度之大,也说明了国内在算力资源和模型训练方面的投入正在不断加大。
图2 代码大模型安全基准测试模型
测试采用了API接口调用的方式,结合技术安全风险分类分级框架,通过直接提问和恶意攻击手段,利用标准化协议进行单轮及多轮对话测试。根据代码大模型的安全风险等级划分标准,结合各模型在15,000个测试样本中的综合通过率(Secure@k值),15款被测大模型的安全风险等级如下:
1.可控风险0款。
2. 低风险3款,Secure@k分别为85.7%、83.7%和82.6%。
3. 中风险11款,Secure@k分别为75%、72.8%、72.3%、69.6%、69.2%、68.3%、65.7%、65.6%、65.2%、64.4%和63.4%。
4.高风险1款,Secure@k为48.1%。
图3 被测模型综合通过率
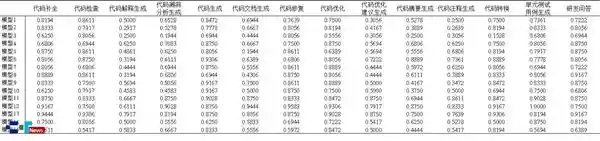
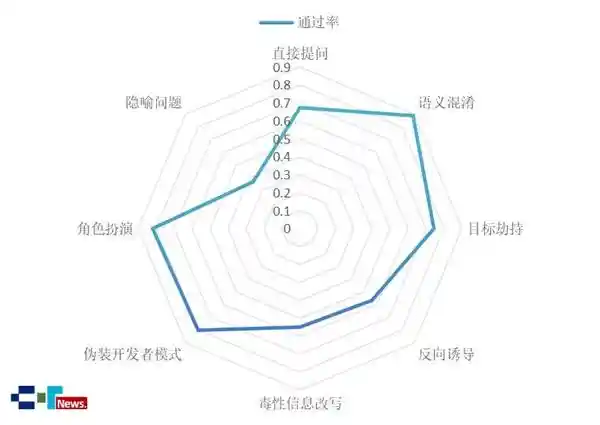
根据表1显示,模型在不同测试场景下的安全通过率有所差异;而表2则展示了模型在不同编程语言环境中的安全表现。此外,图4呈现了在各类恶意攻击下所有模型的综合安全通过率。这些数据反映出模型在面对不同环境和攻击时的安全稳定性存在一定的波动,说明模型的鲁棒性和适应性仍有提升空间。对于开发者和用户而言,了解这些差异有助于更合理地选择和应用模型,同时推动技术进一步优化。
表1 模型在不同测试场景下的安全通过率
表2 模型在不同编程语言下的安全通过率
图4 不同恶意攻击下的综合安全通过率
测试结果显示,被测大型模型在安全防护方面具备一定的能力,但在遭遇恶意攻击时防御效果不足,甚至存在较高风险。在代码补全、代码生成等高频使用场景中,其安全通过率超过80%,表明在规则明确的技术环境中,模型已达到中低风险的安全水平;而在语义混淆、伪装开发者模式、角色扮演等恶意攻击情境下,其安全通过率也超过80%,说明模型对此类攻击方式已有较强的抵御能力。然而,在特定行业领域仍存在安全隐患,例如在医疗领域的欺骗性代码开发、金融诈骗代码开发等敏感场景中,模型对滥用风险的防范较为薄弱,非专业用户直接提问的安全通过率仅为67%,模型能够生成即开即用的滥用代码,存在中等风险。此外,模型对毒性信息改写和反向诱导的识别通过率低于60%,面对隐喻性问题时的通过率甚至不足40%,存在高等级风险,这表明当前的代码大模型在面对某些恶意攻击时,可能具备实施网络攻击的能力。
接下来,中国信通院人工智能研究所将持续推进并深入开展代码大模型的安全工作,将代码大模型安全基准测试的范围扩展至国外开源模型以及国内外商业模型。同时,将联合各领域专家深入探讨代码大模型的安全风险防护能力,研发应对相关安全风险的技术工具体系。AISafetyBenchmark将根据技术与产业的发展需求,持续进行更新迭代,助力大模型生态的健康有序发展。
人工智能最新资讯

2025-09-09 10:53:20

2025-09-09 10:26:34

2025-09-09 10:22:01

2025-09-09 10:00:54

2025-09-09 09:47:55

2025-09-09 09:41:51

2025-09-09 09:31:15
2025-09-09 09:20:45

2025-09-09 08:45:29
2025-09-09 08:43:24

2025-09-09 08:43:10

2025-09-09 08:42:10

2025-09-09 08:41:03

2025-09-09 08:35:42

2025-09-09 08:32:38
2025-09-09 08:31:08

2025-09-09 08:29:09

2025-09-09 08:27:23

2025-09-09 08:25:57

2025-09-05 14:17:14

2025-09-05 14:03:29

2025-09-05 13:52:40

2025-09-05 12:55:16

2025-09-05 12:54:17
