国产GPU突破性进展!摩尔线程、砺算齐推FP8,英伟达H20停产背后有何玄机?
国产GPU迎重大突破,FP8技术引爆算力革命
8月25日消息,DeepSeek发布v3.1版本后,官方透露下一代国产芯片设计UE8M0FP8即将面世。该芯片采用指数位8位、尾数位0位的FP8子格式,专为矩阵乘法等AI核心运算进行优化设计,旨在提升计算效率与能效比。 从技术角度来看,FP8作为一种低精度浮点格式,在保证一定计算精度的同时大幅降低数据存储和传输成本,非常适合用于大规模AI模型的训练与推理。此次国产芯片对FP8的深度适配,不仅体现了国内在AI硬件领域的持续突破,也反映出在关键核心技术上自主可控的迫切需求。随着AI应用的不断扩展,这类针对特定计算场景优化的芯片将发挥越来越重要的作用。

凭借这条消息,国产算力领域迅速引发关注,随后摩尔线程、砺算科技等国内优秀的GPU厂商也第一时间作出回应。
DeepSeek-V3.1采用UE8M0FP8Scale的参数精度,被看作是国内AI芯片迈向新阶段的重要信号。毕竟,单纯地“堆卡”已无法完全满足实际需求,提升单张卡片的效率以及优化集群调度同样至关重要。
DeepSeek对下代国产芯片的预告,也让国产算力生态有了新的前景,包括芯片、框架、算力平台到应用层的闭环适配。
在当前行业发展的大背景下,摩尔线程已确认,其产品目前已原生支持FP8,并能够支持DeepSeek的相关功能。这一进展表明,国内企业在高性能计算和AI芯片领域正持续发力,逐步缩小与国际领先水平的差距。随着技术的不断突破,更多应用场景将被打开,也为国产算力生态的建设提供了有力支撑。
摩尔线程表示,其产品支持从FP64到INT8的完整精度谱系,是国内少数具备FP8大模型训练能力的厂商之一。通过采用FP8混合精度技术,显著提升了训练与推理的一体化能力,在主流前沿大模型训练中实现了20%至30%的性能提升。 在当前人工智能技术快速发展的背景下,算力和精度的平衡成为关键。摩尔线程在精度谱系上的全面布局,不仅体现了其在高性能计算领域的技术实力,也为大模型训练提供了更灵活、高效的解决方案。FP8的引入,尤其在降低训练成本的同时提升性能,具有重要的现实意义。这一技术突破或将推动国内AI生态的进一步完善与创新。
此外,东芯股份在互动平台上表示,砺算科技专注于开发多层次(可扩展)图形渲染GPU芯片,其产品能够支持端侧、云端和边缘端的主流图形渲染及AI加速功能。
其7G100系列GPU芯片支持单精度浮点运算、半精度浮点运算以及8位整数运算等多种计算任务。不同精度的计算方式在性能、资源占用和效率方面存在差异,因此适用于不同的应用场景。
随着国产算力芯片技术的不断突破,加上生态系统的协同支持,这也成为国内厂商摆脱依赖英伟达H20的关键力量。
人工智能最新资讯

2025-09-09 10:53:20

2025-09-09 10:26:34

2025-09-09 10:22:01

2025-09-09 10:00:54

2025-09-09 09:47:55

2025-09-09 09:41:51

2025-09-09 09:31:15
2025-09-09 09:20:45

2025-09-09 08:45:29
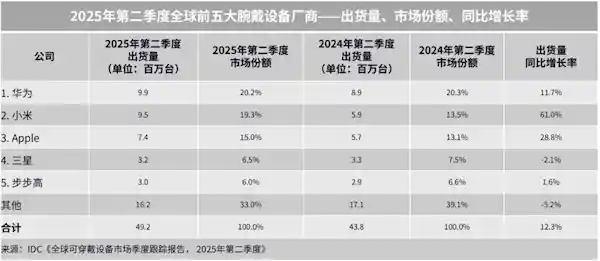
2025-09-09 08:43:24

2025-09-09 08:43:10

2025-09-09 08:42:10

2025-09-09 08:41:03

2025-09-09 08:35:42

2025-09-09 08:32:38
2025-09-09 08:31:08

2025-09-09 08:29:09

2025-09-09 08:27:23

2025-09-09 08:25:57

2025-09-05 14:17:14

2025-09-05 14:03:29

2025-09-05 13:52:40

2025-09-05 12:55:16

2025-09-05 12:54:17
