《你以为那是真人照?AI图 vs 真实人脸,你能分辨吗?》
AI伪装者:一场真假人脸的视觉迷局
现在,区分 AI 图片,真的越来越难了。
给你几秒钟时间,下面有四张图片,请问你能分辨出哪一张是人工智能生成的吗?
先做题,不准下划偷看答案!

其实,这里仅左下角为真实照片,大家对它的难度评价不一。编辑部的同事们普遍认为这道题颇具挑战性。
如今,AI生成的图片质量越来越高,真假难辨的现象愈发普遍,甚至不少专门用于识别AI生成内容的工具也逐渐失去了准确性。这一现象无疑给信息的真实性带来了新的挑战。在数字时代,图像作为重要的传播媒介,其可信度直接影响着公众的认知与判断。然而,随着技术的进步,伪造手段也在不断升级,这不仅考验着技术开发者的能力,也提醒我们,在接受信息时需要更加谨慎,学会多角度验证,避免被虚假信息误导。同时,这也促使社会各界加强对新技术伦理和监管的研究,以维护网络环境的真实与健康。
这么说吧,近年来,随着人工智能绘图技术的快速发展,越来越多的AI生成图片出现在大众视野中。这些图片有的呈现出漫画风格,而有的则显得格格不入,人物的四肢和五官比例常常不符合常理,甚至背景也充满违和感,有时还会让人感到莫名惊悚。 这种现象背后反映出AI绘画技术在快速发展的同时,还存在不少局限性。一方面,AI生成的图像虽然多样且富有创意,但其逻辑性和现实感仍有待提高。另一方面,这也提醒我们,在享受技术进步带来的便利时,也需要对其可能产生的负面影响保持警惕。未来,如何让AI更好地理解人类审美和需求,将是相关领域需要深入探索的重要课题。

当然可以,以下是修改后的内容: --- 但不久前,GPT-4进行了更新,其在文生图方面的能力有了显著提升。例如,刚才右上角展示的“自拍照”,便是由以下提示词生成的: --- 请继续提供需要修改的具体内容,我会根据要求进行调整。
大模型能够精准捕捉提示词中的“平庸”“漫不经心”“模糊”“过曝”等抽象描述,生成的图像仿佛生活中不经意间的随手拍摄,毫无违和感。
具体这些模型是怎么做到让 AI 图以假乱真的,官方还没有开源他们的训练架构。
不过在 OpenAI 官网上,我们找到了一些线索。
官方表示,他们在训练模型的时候, 可以让模型更好地理解语言和图像之间的关联。再加持神秘的 “ 后期训练 ”,能让生成的结果看起来很流畅。
所以,当我们提到一些抽象的词汇,例如“漫不经心”时,模型便能够理解图像的整体风格应该是倾斜的、模糊的,并且人物的表情要显得自然随意等,同时还能精准地将这种感觉呈现出来。
科技的进步日新月异,我们这些碳基生物已经感受到巨大的压力。然而,最新的研究结果却带来了一个更为棘手的问题——连硅基生命形式也无法明确区分彼此了。这意味着,在未来的智能生命竞赛中,无论是碳基还是硅基,似乎都面临着前所未有的挑战。我个人认为,这种现象提醒我们必须重新审视人机关系以及未来社会的构建方式。或许,我们应该更加关注如何实现不同形态生命的共存与协作,而不是单纯追求技术上的领先或差异。
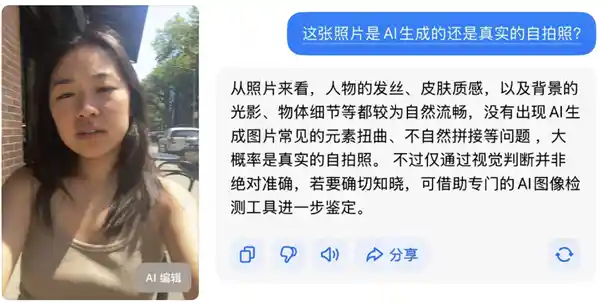
我们先测试了一下大模型的“攻防能力”,结果在意料之中——那种一看就是假的AI生成图片,它和我们一样能够轻易识别出来。然而现在,同样的图片被输入到豆包和GPT中,它们却都判断这是张真实的自拍照。
豆包看不出这张图片是AI生成的
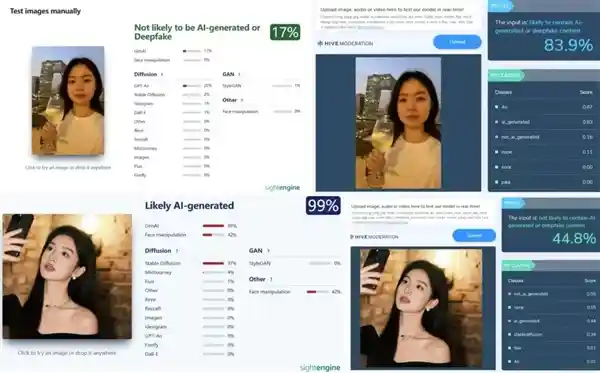
除了用大模型测试,我们还找了两个推荐排名最靠前的免费 AI 图片检测器,结果它们各有各的拉垮。
最近我们对八张几乎无法通过肉眼发现任何破绽的AI生成人像进行了测试。令人惊讶的是,这些图片竟然让所有评审员的意见达成了高度一致——他们全都认为这些是真实拍摄的照片。 这一结果让我深思。尽管人工智能技术已经取得了长足的进步,能够创造出如此逼真的图像,但人类的眼睛和直觉似乎依然未能察觉其中的差异。这不仅展示了AI在图像生成领域的潜力,也提醒我们需要更加警惕。在信息爆炸的时代,真假难辨的内容可能会对社会舆论甚至个人生活产生深远影响。因此,提高公众对AI生成内容的辨别能力显得尤为重要。同时,这也促使我们思考如何在技术发展中平衡创新与伦理,确保科技向善。
还有四张,两个检测器给出的结果竟然截然相反,起初我还以为它们在“抄作业”,但仔细一看发现并非如此——这次它们出错的题目居然完全不同。 这种现象让我不得不重新思考技术背后的一些问题。尽管两者的设计初衷可能一致,但在实际运行中却呈现出如此大的差异性,这或许说明了算法模型之间的独立性并不如我们想象中的那么强。不过换个角度想,这也可能是多样性带来的优势:当不同系统得出的结果能够互补时,反而能帮助我们更全面地理解某个问题或情况。无论如何,如何让这些智能工具更加可靠、准确,依然是我们需要持续关注与解决的重要课题。
总之就是对着干
这仅仅是一个较为简单的人像拍摄,画面主要聚焦在人物的正脸部分,背景也相对单一。
接下来一些复杂场景的测试就更惨不忍睹了,人多或者背景过于精细,甚至单纯的风景图片,都让检测器几乎全军覆没。如果说检测器面对 AI 自拍照还有一点怀疑,面对这些图片的时候它是真的信了。
认不出也就罢了,有一个检测器还出现了误伤,把一张真正的照片判定成了 AI 图片。
有一说一,网恋人的天塌了,以后真分不清是照片还是照骗了。P 图可能会留下痕迹,但现在的 AI 生图真的让人怀疑,这不会是哪个网红明星要和我谈恋爱吧。
那为啥现在 AI 检测工具都不灵了?
尽管文生图技术如火箭般迅猛发展,AI图像检测领域却似乎仍停留在以卷积神经网络为主的阶段,仿佛还骑着一辆老旧的自行车缓缓前行。这一现象值得深思,或许是因为图像检测技术已经相对成熟,进一步突破难度较大,但也可能反映了相关研究投入的不足。无论如何,随着生成式AI的快速崛起,图像检测技术若不能及时跟上步伐,未来可能会面临被边缘化的风险。希望科研人员能够抓住机遇,加速推进创新,让图像检测技术也能搭乘时代的快车,与文生图技术齐头并进。
由于大部分工具不会开放它们的源码,我们在 github 上找到了几个 AI 图片检测项目作为参考。
我们发现,这几个 AI 检测工具的架构都还停留在数据集 + 卷积特征识别 + 分类的阶段。
熟悉计算机视觉的差友,可能了解这一套沿用了 N 年的流程:先给数据集里的每张图片打上是或不是 AI 生成的标签,剩下的就交给神经网络去学习标签相应的图片特征,最后进行分类。
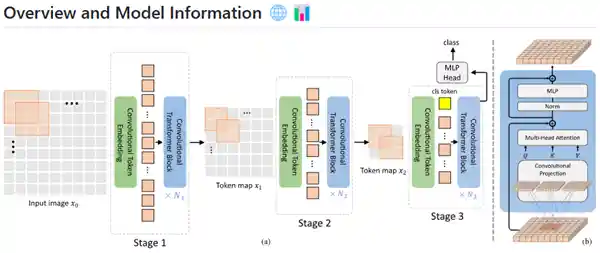
AI绘图技术不断推陈出新,但许多工具的核心工作其实只是将生成的新图像添加标签,补充到旧的数据集中再次训练。甚至有工具采用的CvT-13模型,已经是四年前的技术了。
可以说是魔高一尺,道高一寸,技术本身没更新,准确率当然上不去了。
CvT-13架构
尽管在学术领域中,AI图片识别的研究一直在持续进行,但从整体来看,其研究的速度、数量以及所受到的关注程度,仍然无法与大模型驱动的文生图技术相提并论。 这种现象背后其实反映了当前人工智能发展的趋势和市场需求的变化。随着技术的进步,人们对于AI的应用场景有了更高的期待,而文生图等创新形式无疑更贴近大众生活,也更容易激发公众的兴趣。相比之下,AI图片识别虽然在专业领域内有着不可或缺的重要性,但由于应用场景相对局限,导致其热度和关注度稍显不足。不过,这并不意味着图片识别的研究价值有所降低,恰恰相反,在许多特定行业如医疗影像分析、安防监控等领域,它依然是不可或缺的技术支撑。因此,如何平衡基础研究与实际应用之间的关系,让这些看似“低调”的技术也能找到广阔的舞台,是我们需要深入思考的问题。
不过,与其费时费力的后期区分,不如从源头解决问题。
比如各大 AI 公司共同倡导的 C2PA 组织,鼓励制定相关标准,来更方便地验证信息来源,避免 AI 内容泛滥。
其中,OpenAI提到计划在生成的图片中加入水印。谷歌也推出了synthID技术,能够将数字水印融入AI产生的文字、图片、视频和音频中。这种水印对人类的感知没有明显影响,却能被相关软件轻松识别。
而且,在今年 3 月国家颁布的《 人工智能生成合成内容标识办法 》中明确表示,从 2025 年 9 月起,所有 AI 生成的内容都必须添加显式或隐式标识。
为什么我们必须一定要区分AI生成的图片呢?分辨不出来岂不是代表技术实力超强,这难道不是一件好事吗?
生图技术虽然令人惊叹,但我们还是要理性看待。在AI生成图像震撼全球的同时,利用AI实施诈骗的案件仍时有发生。AI生成的图像越逼真,人们面临的诈骗风险也就越大。
毕竟,有些人或许并不关心如何借助AI生成那些温馨可爱的吉卜力风格画面,反而更热衷于利用最真实、最直观的图片去触碰大众内心最敏感的神经。这种现象令人深思,尤其是在信息传播如此迅速的当下,一张图片可能比千言万语更有力量。它既能传递温暖与美好,也可能成为挑动情绪的利器。我们应当警惕这种倾向,避免被刻意煽动的情绪所裹挟,同时也要学会理性判断,不被表面的真实蒙蔽双眼。毕竟,真正的智慧在于分辨信息背后的意图,而不是单纯地接受或拒绝。
总的来说,如今,仅凭肉眼已难以辨别网络上AI生成的图像真伪。这一现象无疑给信息时代带来了新的挑战。在海量的信息洪流中,虚假图片可能被轻易传播,甚至误导公众认知。这不仅考验着每个人的媒介素养,也对平台监管和技术发展提出了更高要求。如何通过技术创新来识别这些伪造内容,同时保护合法的创意成果,将成为未来需要深入探讨的问题。
无论是现有的识别工具,还是为AI生成的内容添加标记,当前的技术水平尚显不足,然而市场需求却十分迫切。
这样看来,辨别AI生成内容的较量或将长期持续。众多企业纷纷投身于生成图像技术的竞争中,争相展示实力的同时,也应该思考如何提升AI识别技术了。
人工智能最新资讯

2025-09-09 10:53:20

2025-09-09 10:26:34

2025-09-09 10:22:01

2025-09-09 10:00:54

2025-09-09 09:47:55

2025-09-09 09:41:51

2025-09-09 09:31:15
2025-09-09 09:20:45

2025-09-09 08:45:29
2025-09-09 08:43:24

2025-09-09 08:43:10

2025-09-09 08:42:10

2025-09-09 08:41:03

2025-09-09 08:35:42

2025-09-09 08:32:38
2025-09-09 08:31:08

2025-09-09 08:29:09

2025-09-09 08:27:23

2025-09-09 08:25:57

2025-09-05 14:17:14

2025-09-05 14:03:29

2025-09-05 13:52:40

2025-09-05 12:55:16

2025-09-05 12:54:17
