阿里通义千问Qwen3系列重磅发布:解锁256K超长上下文能力
超越想象!Qwen3系列引爆256K超长上下文新时代
4月28日最新消息,阿里通义千问开源团队的林俊旸在社交平台发文透露,Qwen3模型或于今日正式发布。
值得注意的是,Qwen3系列模型集合曾在阿里巴巴旗下的AI模型开源社区ModelScope(魔搭)短暂展示后即下架,其中包括Qwen3-4B-Base、Qwen3-1.7B、Qwen3-0.6B以及Qwen3-30B-A3B-Base四款模型。这些模型均遵循Apache License 2.0开源协议。虽然官方尚未公布正式说明,但依据命名规则和前代的技术逻辑,可以推测其技术路线与定位方向。
此次发布的Qwen3系列模型展现了多样的参数配置与技术路线选择。其中,Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B以参数规模直接命名,分别拥有40亿、17亿和6亿参数量。这种简洁的命名方式或许暗示这些模型采用了单一架构的稠密设计,没有采用混合专家(MoE)机制,这可能意味着它们更倾向于在轻量化场景下发挥优势,比如移动设备端应用或者对成本敏感的企业服务。 另一方面,Qwen3-30B-A3B-Base作为一款基于MoE架构的基础模型,总参数达到300亿,但动态调用部分仅为30亿。这种设计思路显示出该模型在兼顾性能的同时,还能根据具体任务灵活调整资源分配,从而实现更高的效率和更强的适应性。从市场角度来看,这样的布局既满足了追求高性能计算的需求,也为更广泛的轻量级应用场景提供了可能性。整体而言,Qwen3系列展示了强大的技术实力和丰富的应用场景覆盖能力,未来在不同领域中的表现值得期待。
另据AIbase消息,Qwen3具备高达256K的上下文长度,能够应对推理和非推理任务。
据了解,自2023年8月以来,阿里云陆续推出了Qwen系列的四代模型,从Qwen到Qwen2.5,覆盖了从小到大的全尺寸范围,包括0.5B、1.5B、3B、7B、14B、32B、72B直至110B,展现了其在人工智能领域的深厚积累和技术实力。这些模型不仅涵盖了大语言处理,还延伸至多模态、数学推理以及代码生成等多个领域,充分体现了阿里云在技术多元化方面的布局与探索。 在我看来,阿里云这一系列动作不仅是对自身技术研发能力的一次集中展示,也是对未来AI发展趋势的一种引领。尤其是针对不同应用场景设计的不同规模模型,能够更好地满足企业和开发者多样化的需求。此外,在多模态融合方面取得的进步尤为值得关注,这意味着未来的AI产品将更加智能化、人性化,能够在更多复杂场景下提供高效解决方案。总体而言,这是一次具有里程碑意义的技术突破,相信它会推动整个行业向着更高水平迈进。
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
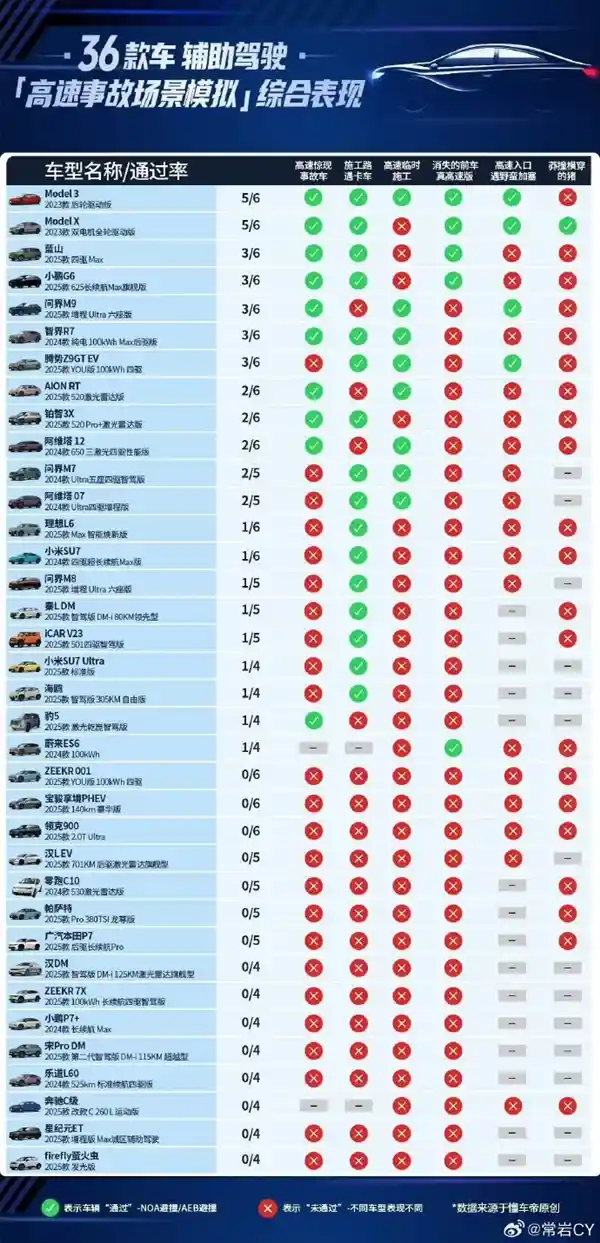
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
