混元视频神器开源了!多模态合一,从此创作不设限
混元视频神器震撼开源!多模态融合引爆创作新时代
5月9日消息,腾讯混元今日正式发布并开源了一款全新的多模态定制化视频生成工具——HunyuanCustom。该工具依托于混元视频生成大模型(HunyuanVideo)构建,其主体一致性表现超越了现有开源方案。
据介绍,HunyuanCustom集成了文本、图像、音频与视频等多种模态的输入功能,能够生成高质量的视频内容,是一款在创意表达和生成质量上表现突出的智能视频创作工具。在我看来,这款工具的诞生不仅标志着人工智能技术在跨模态领域的进一步突破,也为传统媒体行业提供了全新的创作思路。特别是在当下信息爆炸的时代,如何高效地整合不同形式的内容来传递核心信息变得尤为重要。HunyuanCustom通过其强大的整合能力,可以帮助创作者快速产出兼具深度与广度的作品,这对于提升新闻报道的质量和效率具有重要意义。同时,它也为普通用户降低了参与视频创作的门槛,让每个人都能轻松实现创意表达。不过,随着技术的进步,我们也需要关注其可能带来的版权及伦理问题,确保技术应用始终服务于人类社会的整体利益。总之,HunyuanCustom的推出无疑为多模态智能创作开启了一扇新大门。
腾讯表示,Hunyuan Custom 模型能实现单主体视频生成、多主体视频生成、单主体视频配音、视频局部编辑等能力,其生成的视频与用户输入的参考主体能保持高度一致。
其中,单主体生成能力已经开源并在混元官网(附官网地址:https://hunyuan.tencent.com/)上线,用户可以在“模型广场-图生视频-参考生视频”中体验,其他能力将于 5 月内陆续对外开源。
通过HunyuanCustom,用户仅需上传一张包含目标人物或物体的图片,同时附上一段文字描述(如“她正在浇花”),该工具即可精准识别图片中的身份特征,并在全新的动作、服饰及场景下生成流畅且真实的视频内容。
除了单主体以外,这个能力同样能实现多主体视频的生成,用户提供一张人物和一张物体的照片(比如一包薯片和一名男子的照片),并输入文字描述(比如“一名男子正在游泳池旁边,手里拿着薯片进行展示”),即可能让这两个主体按要求出现在视频里。
此外,HunyuanCustom不仅限于图像与文本的结合,更拥有出色的扩展功能。在音频驱动(单主体)模式下,用户能够上传人物图像并搭配音频语音,模型即可生成人物在各种场景中说话、唱歌或进行其他音视频同步展示的效果,可广泛应用于数字人直播、虚拟客服、教育演示等多个领域。
HunyuanCustom 在视频驱动模式下能够帮助用户将图片中的人物或物品无缝替换或添加到任何视频片段里,从而实现创意植入和场景拓展,让用户可以便捷地完成视频重组与内容优化。
过去大多数视频生成模型主要支持文本到视频以及图像到视频的转换。文本到视频的方式每次都需要基于新的提示词重新生成,这使得在生成过程中很难维持人物和场景的一致性。而图像生成视频的技术则更多是实现“让图片动起来”的效果。比如,上传一张人物照片后,生成的视频往往局限于原照片中的服饰、姿态和场景,仅能在有限范围内展现固定的表情或动作,对服装、背景和姿态的调整能力非常有限。
多模态视频生成技术的发展为创作者提供了更多可能性。传统的视频生成模型往往难以在保持人物形象一致的同时灵活调整其背景与动作,而HunyuanCustom的出现填补了这一空白。通过创新的身份增强机制与多模态融合模块,该模型能够精准捕捉输入图像中的人物特征,并结合文本描述实现对场景与动态的自由定制。这不仅大幅提升了创作效率,也为艺术表达开辟了新路径。 在我看来,这种技术突破对于影视制作、广告设计乃至教育领域都有着重要意义。它让创意不再受限于技术瓶颈,使创作者能更专注于内容本身,激发无限灵感。不过值得注意的是,在享受便利的同时也需要警惕滥用风险,比如版权争议或隐私泄露等问题。因此,如何合理规范此类技术的应用将是未来值得探讨的方向之一。
参考资料:
体验入口:https://hunyuan.tencent.com/modelSquare/home/play?modelId=192
项目官网:https://hunyuancustom.github.io/
代码开源:https://github.com/Tencent/HunyuanCustom
论文地址:https://arxiv.org/pdf/2505.04512
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
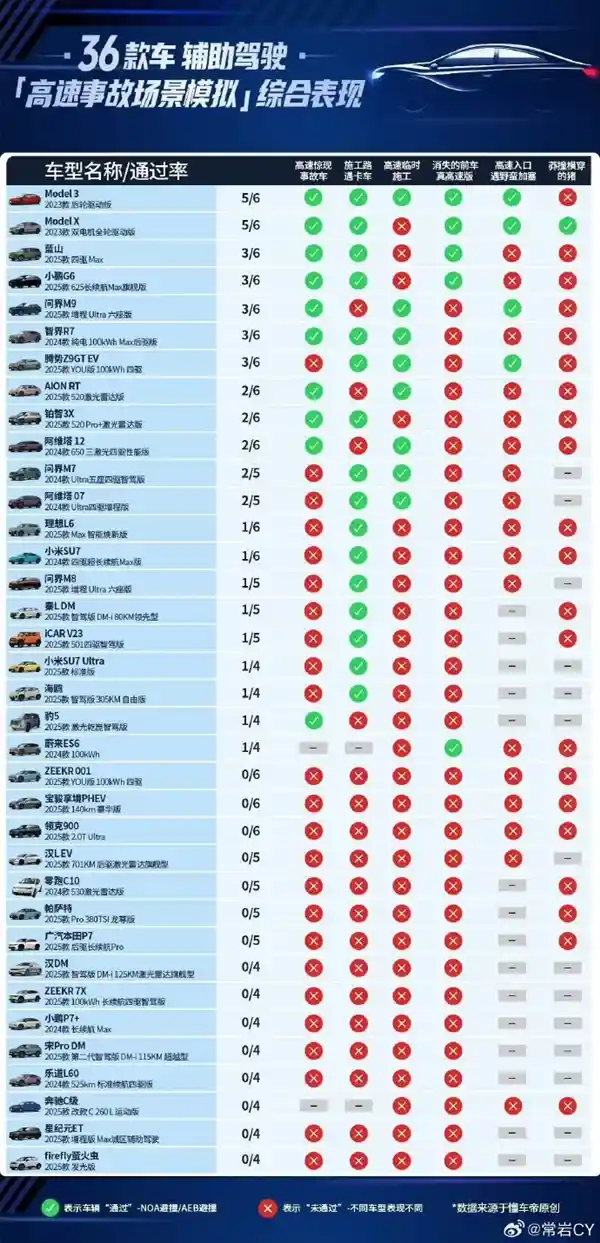
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
