哥伦比亚大学研究揭示:AI搜索工具信心满满却准确率仅六成
AI搜索工具:信心满满的背后隐藏着六成准确率的真相
3月13日消息,据外媒Techspot报道,哥伦比亚大学数字新闻研究中心近期针对八款主流AI搜索引擎进行了深入研究,其中包括ChatGPTSearch、Perplexity、PerplexityPro、Gemini、DeepSeekSearch、Grok-2Search、Grok-3Search以及Copilot。研究人员通过一系列测试评估了这些搜索引擎的准确性和信息检索能力,并特别关注了它们在面对复杂或敏感问题时的表现,同时也记录了各平台拒绝回答问题的频率。 这项研究为公众了解当前AI技术在搜索领域的应用现状提供了重要参考。从结果来看,尽管AI搜索引擎在处理常规问题时已展现出较高的效率与可靠性,但在涉及深度分析或特定领域知识的问题上仍存在一定局限性。此外,部分模型选择性地回避某些话题的现象也引发了关于其透明度与责任性的讨论。这不仅提醒开发者需进一步优化算法逻辑,也为用户敲响警钟——即在依赖AI工具获取信息的同时,仍需保持批判性思维,避免盲目信任机器输出的结果。 总体而言,这项研究既是对现有技术的一次客观检验,也是对未来发展方向的重要指引。随着人工智能技术不断进步,如何平衡技术创新与伦理考量将成为行业发展的关键课题。
研究人员从20家知名新闻机构中随机选取了200篇报道进行分析,每家机构提供10篇被谷歌搜索排名前三的文章。随后,他们使用相同关键词对多种AI搜索引擎进行了测试,重点考察这些工具能否准确引用报道的核心内容、所属新闻机构的名称以及原始链接信息。 这项研究不仅揭示了当前AI技术在处理新闻信息方面的潜力,也暴露出一些潜在的问题。例如,在信息提取过程中,部分AI工具可能会忽略细节或误读原文,这可能影响用户对新闻真实性的判断。同时,这也提醒我们,在依赖AI辅助获取新闻时,仍需保持一定的批判性思维,仔细核对来源以避免被误导。 总体而言,这一实验结果为我们提供了宝贵的参考,有助于推动AI技术更精准地服务于公众的信息需求,同时也强调了媒体行业与科技领域合作的重要性,共同构建更加透明可信的信息环境。
测试表明,除了Perplexity及其付费版本外,其他AI搜索引擎的表现均较为逊色。综合来看,这些AI搜索引擎给出的答案中有六成存在准确性问题,且AI对错误答案表现出的过高置信度进一步加重了这一问题。
这项研究表明,外界对于大语言模型的担忧并非空穴来风。这些模型不仅容易犯错,而且在面对错误时表现得异常“自信”,甚至会用看似权威的方式传播不实信息。这种现象值得警惕,因为它可能对依赖这些技术的人们造成误导。例如,在教育或医疗等需要高度准确性的领域,这种“一本正经地胡说八道”可能会带来严重后果。因此,如何让大语言模型更谨慎地处理信息,避免过度自信,将是未来研究的重要方向。同时,用户在使用这类工具时也应保持批判性思维,不可盲目相信输出结果。这不仅是对技术的合理期待,也是对使用者自身负责的表现。
即便已经承认存在错误,ChatGPT依然可能在后续的回答中继续虚构内容。在大语言模型的设计逻辑下,它们几乎总是倾向于“无论如何都要给出答案”。相关研究数据也验证了这一点:ChatGPTSearch是唯一一个对全部200个新闻查询都作出回应的AI工具,但其“完全正确”的比例仅为28%,而“完全错误”的比例却高达57%。
ChatGPT 并非表现最糟的。X 旗下的 Grok AI 表现尤为不堪,其中 Grok-3 Search 的错误率高达 94%。微软 Copilot 也问题重重 —— 在 200 次查询中,有 104 次拒绝作答,剩下的 96 次中,仅 16 次“完全正确”,14 次“部分正确”,66 次“完全错误”,总体错误率接近 70%。
多家AI工具开发公司虽然未公开承认存在相关问题,却依然向用户收取每月20至200元人民币不等的订阅费用。值得注意的是,付费版PerplexityPro(20元/月)与Grok-3Search(40元/月)相较于免费版本提供的答案数量更多,但其错误率也相对更高。
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
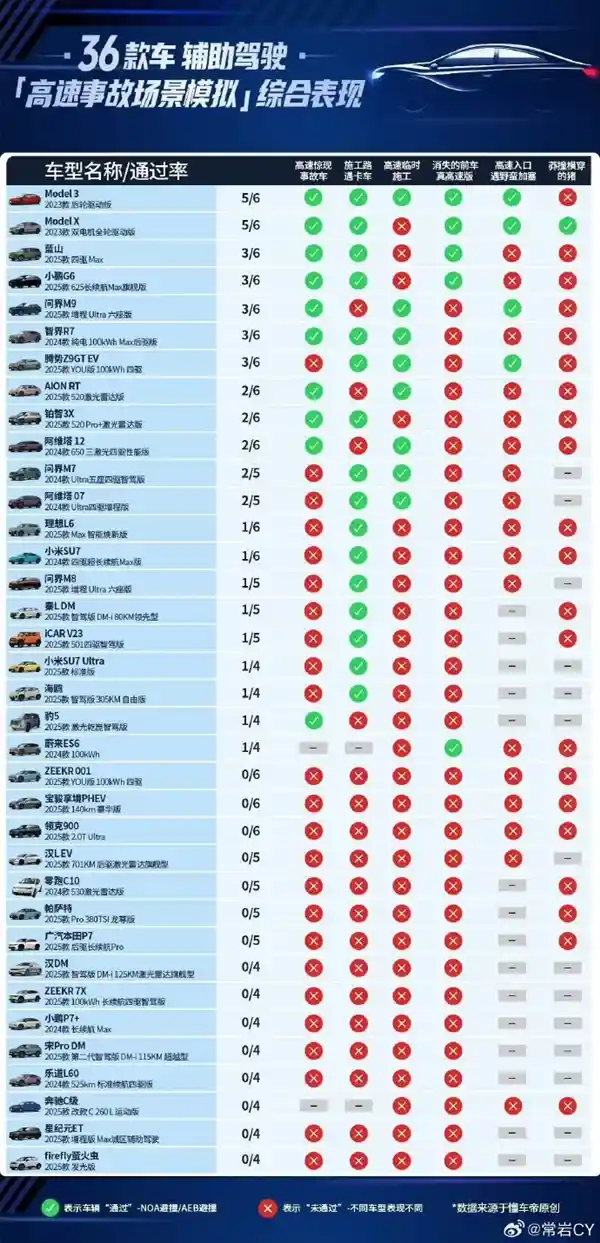
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
