英伟达创造全新 AI 推理性能纪录:DeepSeek-R1 模型实现巅峰突破
AI 推理巅峰突破!英伟达重塑智能未来
3月19日消息,英伟达在NVIDIA GTC 2025大会上宣布,其NVIDIA Blackwell DGX系统在DeepSeek-R1大模型的推理性能测试中刷新了世界纪录。这一成就不仅彰显了英伟达在AI硬件领域的领先地位,也进一步证明了其在推动人工智能技术发展的决心与实力。随着AI应用的不断扩展,高性能计算平台的重要性日益凸显,而Blackwell DGX系统的出色表现无疑为行业树立了新的标杆。这不仅意味着企业在部署大规模AI任务时可以拥有更高效的解决方案,也为科研机构提供了更为强大的工具以加速前沿研究的进程。未来,我们期待看到更多基于此类先进平台的应用落地,让AI技术更好地服务于社会各个领域。
据介绍,搭载八块Blackwell GPU的单一DGX系统运行6710亿参数的完整版DeepSeek-R1模型时,能够为每位用户提供每秒超过250个token的响应速度,系统的最高吞吐量更是突破每秒3万token。
英伟达表示,随着NVIDIA不断推动技术前沿,在最新的Blackwell Ultra GPU和Blackwell GPU上持续刷新推理性能的上限,这一进步无疑将为行业带来深远影响。这些新一代芯片不仅展示了硬件设计上的巨大飞跃,也再次证明了NVIDIA在人工智能计算领域的领导地位。对于开发者和企业而言,这意味着他们能够以更高的效率部署复杂的AI模型,从而加速创新步伐。我个人认为,这种对高性能计算的不懈追求,不仅是对现有技术瓶颈的一次次突破,更是对未来应用场景潜力的深刻挖掘。我们有理由期待,在这类尖端技术的支持下,更多前所未有的应用场景将被解锁,进一步推动整个社会向智能化方向迈进。
单节点配置:DGX B200(8 块 GPU)与 DGX H200(8 块 GPU)
测试参数:最新的测试采用了TensorRT-LLM内部版本,输入长度为1024个token,输出长度扩展至2048个token;而之前的测试中,输入和输出均为1024个token;同时支持并发处理。
计算精度:B200 采用 FP4,H200 采用 FP8 精度
英伟达表示,借助硬件与软件的协同优化,自2025年1月起,他们成功将DeepSeek-R1671B模型的吞吐量提升了大约36倍。
节点配置:DGX B200(8 块 GPU)、DGX H200(8 块 GPU)、两个 DGX H100(8 块 GPU)系统
测试参数:在使用TensorRT-LLM内部版本进行模型推理时,我发现其性能表现依旧出色。与之前测试的输入输出均为1024token的情况相比,这次我们将输入提升至1024token,而输出扩展到了2048token,这无疑是对模型处理能力的一次重要挑战。同时,在并发性达到最大值的情况下,整个系统的运行依然稳定流畅。 从实际应用的角度来看,这种能够支持更大规模输入输出的模型无疑具有更广泛的应用前景。尤其是在面对复杂任务或者需要生成较长文本的情况下,如撰写深度报道或分析报告等场景,这样的模型表现将极大提升工作效率。此外,随着并发性的提高,未来在多用户同时访问、大规模数据分析等领域也将展现出更强的竞争力。 当然,我们也应该注意到,尽管当前技术已经取得了显著进步,但在实际部署过程中仍需关注硬件资源的合理配置以及算法优化等问题,以确保模型能够在各种环境下都能发挥出最佳性能。总的来说,这项成果标志着自然语言处理技术又向前迈进了一步,值得我们给予高度评价和支持。
计算精度:B200 采用 FP4,H100 / H200 采用 FP8 精度
与Hopper架构相比,Blackwell架构搭配TensorRT软件能够带来明显的推理性能优化。
英伟达表示,DeepSeek-R1、Llama3.1405B和Llama3.370B在运行TensorRT软件并采用FP4精度的情况下,DGXB200平台相较于DGXH200平台展现了超过三倍的推理吞吐量提升。
英伟达表示,在对深度学习模型进行量化的过程中,如何在低精度计算中最大限度地减少精度损失是一个重要的课题。近期观察到,在DeepSeek-R1模型的应用场景下,采用TensorRT Model Optimizer的FP4训练后量化(PTQ)技术,相较于FP8基准精度,其带来的精度损失几乎可以忽略不计。这一结果表明,该技术在保持高性能的同时,能够有效平衡计算效率与模型精度之间的关系。 从我的角度来看,这种技术的进步为实际应用带来了显著的优势。特别是在资源受限或需要快速响应的场景中,如边缘计算设备或实时推理任务,FP4量化技术能够在保证模型性能的前提下大幅降低硬件需求和运行成本。这不仅推动了人工智能技术的普及,也为更多行业提供了拥抱智能化转型的可能性。未来,随着量化技术的进一步发展,我们或许能看到更加高效且精确的解决方案,从而更好地服务于社会各领域的需求。
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
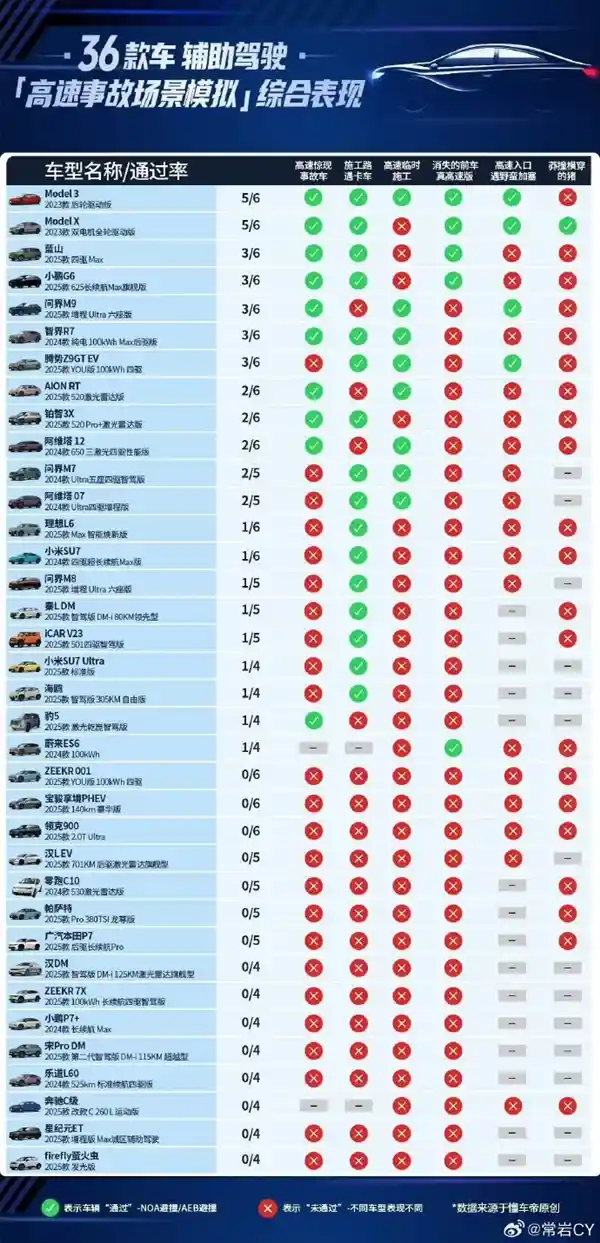
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
