《深探DeepSeek本地部署:意想不到的趣味之旅》
《深探DeepSeek本地部署:解锁AI世界的隐藏宝藏》
随着DeepSeek的兴起,本地部署AI大模型开始逐步走入公众的视线。相比云端版本,本地部署的优势十分显著。它无需连接网络,避免了遇到“服务器繁忙,请稍后再试”的尴尬情况,同时将数据库存储在本地,不仅提升了数据的安全性,还保障了用户的隐私。

DeepSeek大幅降低了AI大模型的部署门槛,让许多普通消费者也能借助个人电脑将其转化为强大的私人助手。尽管如此,运行这些复杂的AI系统仍然对硬件有一定要求,这意味着它并非完全无门槛,但相较于以往的专业设备需求,现在的成本已经友好得多。 在我看来,这种技术进步无疑为更多人打开了通往人工智能世界的大门。对于那些希望尝试新技术但预算有限的用户来说,这是一次难得的机会。同时,这也促使我们思考未来计算资源分配的问题——如何平衡效率与公平,确保每个人都能享受到科技进步带来的便利。

目前,DeepSeek开源项目吸引了众多开发者的关注,他们通过技术手段训练出各种各样的蒸馏模型。这些蒸馏模型有一个共同的特点,即针对低配设备进行了专门优化,使得普通用户也能在自己的电脑上部署AI大模型。然而,在运行效果和精度上,这些模型与高性能版本相比难免存在一定差距,这正是“一分钱一分货”理念的最佳体现。

目前,DeepSeekR1完整版模型参数规模达到671B,这一强大的语言模型为行业带来了新的技术高度。除此之外,它还有多个基础蒸馏版本,包括70B、c、14B、8B、7B以及1.5B等不同参数量级的模型。这些基础蒸馏模型不仅覆盖了广泛的使用场景,还为个人开发者提供了丰富的二次开发空间。这些开发者通过进一步优化和量化处理,推出了适合不同平台和行业需求的定制化版本。这种多样化的模型生态既体现了技术的灵活性,也展示了开源社区的强大活力。在我看来,这种多层次的产品布局能够更好地满足实际应用场景中的多样化需求,同时也能推动整个行业的创新与发展。未来,随着技术的不断进步,相信这类大模型将在更多领域发挥更大的作用。

1.5B是原始最小的模型,搭载一般4G显存和8GB内存的显卡游戏本就能跑。而使用单张显卡不考虑魔改和多卡的话,一般消费级电脑的顶点在32B、70B的蒸馏模型,需要20GB以上显卡搭配64GB以上内存。其实从数字也能看出来高配版和低配版蒸馏模型的差异,1.5B和32B、70B不在一个量级。

我们这次来玩一玩DeepSeek本地部署,给大家出一套简易版本部署教程,首先准备了一套电脑平台,配置如下:

本次我们采用了AMD锐龙9 5900X3D这款全新推出的处理器,它在游戏性能和生产力方面表现出色,目前在双平台均达到了行业顶尖水平。

为了充分发挥这款处理器的性能潜力,我们选用了技嘉X870AELITEWE7ICE主板,这是一款全白设计的主板,具备1622相供电模块,同时配备了全覆盖散热装甲,能够确保AMD锐龙99950X3D完全释放其全部性能。
该主板在拓展能力方面表现出色,不仅配备了PCIe 5.0显卡插槽和M.2插槽,还在I/O区域提供了多达12个USB接口,其中包括两个最新的USB4接口。此外,这款主板还享有4年质保及1年换新服务,为用户提供可靠的售后服务保障。
显卡型号为AORUS GeForce RTX 5090 MASTER ICE 32G,该显卡搭载了基于GB202核心的架构设计,延续了上一代的TSMC 4nm定制工艺(TSMC 4nm NVIDIA Custom Process)。其芯片面积约为750平方毫米。这款显卡配备了21760个CUDA核心,Boost频率高达2655MHz。显存配置方面,它采用了32GB GDDR7规格,显存位宽为512位,显存带宽达到了1792GB/s。此外,该显卡还具备176个光栅单元和680个纹理单元。
这款技嘉FO32U2P OLED显示器是4K级别的高端桌面显示设备,配备了QD-OLED面板,支持240Hz刷新率和0.03ms响应时间,同时通过了Clear MR 13000认证与HDR400认证,能够提供极为逼真的画质体验。
在部署之前,在构建AI工作环境时,选择合适的容器或启动器是一个关键步骤,这与使用StableDiffusion的经历颇为相似,其中“秋叶启动器”就是一个广为人知的选择。当下,有许多支持DeepSeek的容器可供选用,大家可以根据自身需求前往相关官网下载。本次我们将采用LMStudio作为我们的工具平台。在我看来,这种选择不仅体现了对技术生态多样性的尊重,也反映了当前AI开发工具的成熟度和用户友好性。随着越来越多的专业工具涌现,开发者和研究者能够更高效地搭建起适合自己的实验环境,这对推动技术创新具有重要意义。
LM Studio对于新手还是非常友好的,界面简洁干净,逻辑清晰,我们安装打开点击下方齿轮设置,可以调节成简体中文,不过目前中文仅限于一些基础界面和功能调节。
进入正式界面后,你会发现它和大家在网页端看到的样式大致相同,顶部是用来加载模型的。我们已经下载了一款32B版本的模型,加载完成后就可以直接开始对话了。
在使用某些AI生成工具时,用户往往希望对生成过程进行更精细的控制,例如设定字数限制或调整CPU的计算步进等参数。这些参数设置对于追求特定生成效果的人来说尤为重要,尤其是那些希望通过调整细节来获得与他人类似生成结果的用户。比如,在使用Stable Diffusion这类软件时,底部种子就是一个关键选项,它能够直接影响最终的生成质量与风格。 我认为,这种对生成参数的个性化调整功能,不仅体现了技术的进步,也反映了用户需求的多样化。随着人工智能技术的发展,越来越多的应用场景需要更加灵活且可控的服务。允许用户根据自身需求微调参数,不仅能提升用户体验,还能激发更多创意性的应用可能。不过,这也要求开发者持续优化算法,确保即使是在复杂条件下也能保持良好的运行效率和输出质量。未来,我们或许能看到更多针对不同应用场景定制化的AI解决方案出现。
左侧放大镜图标内是LMStudio提供的模型库,其中包含一些经过蒸馏处理的DeepSeekR1模型,用户可以发现多个版本,如27B、12B、4B等已训练完成的模型,可根据实际需求进行下载。需要注意的是,模型的性能越高,所需的系统资源也越多,例如我们正在使用的32B版本就需要占用18GB以上的内存。
如果你不想依赖LMStudio自带的模型,而是选择下载独立的模型,这同样是可以实现的。只需留意界面左侧图表部分显示的文件状态,当顶部提示模型目录时,将你的模型文件复制到对应位置即可。这样,在后续加载模型时,你就能在顶部菜单中轻松找到并使用它了。 在我看来,这种灵活的操作方式为用户提供了更大的自主性和便利性。它不仅打破了对预设模型的单一依赖,还鼓励用户根据自身需求寻找更适合的解决方案。尤其是在技术不断发展的今天,开放性和可定制化已经成为衡量一款软件优劣的重要标准之一。因此,这样的功能设计无疑增强了用户体验,也体现了开发者对用户需求的深刻理解和尊重。
我们这里使用了这个32B模型进行了对话,响应速度极快,整个对话内容生成不到几秒钟。这得益于整个平台性能确实很强大,在跑这个模型时,显存使用了21.5GB左右,内存利用了9GB左右。
这款技嘉平台的AORUS GeForce RTX 5090 DMAX EDITION 32G配备了32GB的大显存,同时内存容量高达64GB,这样的配置为高性能计算提供了坚实的基础。在处理本地32B模型时,充足的内存空间能够确保系统运行更加流畅,大幅提高响应速度。这样的硬件组合不仅能够满足当前高负载任务的需求,也为未来更复杂的应用场景预留了足够的扩展空间。 我认为,对于需要高性能计算的工作环境来说,显存和内存的合理搭配至关重要。大容量的显存和内存不仅能提升工作效率,还能有效避免因资源不足导致的性能瓶颈。尤其是像人工智能训练、大型数据分析这类对硬件要求极高的任务,这套配置无疑是理想之选。从长远来看,这样的投资不仅能够保障系统的稳定性和可靠性,还能在未来的技术发展中占据有利位置。
如果使用的模型过于高端,导致需求量超出显存和内存的承载能力,切记不要盲目运行,因为这样生成的速度会非常缓慢,甚至一分钟也输出不了几个字。这时可以考虑降低模型的蒸馏版本,选择适合自己的配置。
AMD锐龙9 5950X3D在运行时占用率仅为10%,这样的表现意味着用户在进行高强度任务的同时,依然有充足的资源余量来处理其他日常需求。例如,在等待大型渲染任务完成的过程中,可以轻松地切换到观看高清视频或畅玩对显存要求较高的游戏。这种性能与效率的结合无疑为多任务处理提供了极大的便利,尤其适合需要同时兼顾工作与娱乐的专业人士。我个人认为,这款处理器不仅展现了强大的计算能力,更体现了现代芯片设计对用户体验的深刻洞察,尤其是在平衡高性能与低功耗方面取得了显著进步。
本地模型虽然提供了便利,但其局限性也不容忽视。例如,它所依赖的信息完全基于自身的数据库,一旦遇到数据库未涵盖的内容,就可能出现偏差甚至错误。以我最近尝试查询AMD锐龙99950X3D的相关信息为例,由于模型的训练数据截止到2024年,显然无法提供最新的准确信息,反而给出了错误的回答。这提醒我们在面对涉及具体数据的问题时,仍需保持警惕,不可盲目信任AI给出的结果。尽管AI技术发展迅速,但它终究只是一个辅助工具,在实际应用中还需要结合多方验证,才能确保信息的真实性和可靠性。
总结来看,DeepSeek的出现无疑大幅降低了AI大语言模型本地部署的技术门槛,使得普通消费者级别的电脑也能进行实际操作。相比依赖云端服务,本地部署不仅响应速度更快,而且更加私密,能够根据个人需求下载特定模型以满足定制化要求。然而,这项技术依然存在一定的学习曲线,对于一些用户来说可能并不容易上手,尤其是涉及压缩包解压等基础操作时。此外,由于本地模型的更新频率通常低于云端版本,因此在应对热点问题或新知识方面可能会有所滞后。尽管如此,对于希望拥有更快速度和更高隐私保护的用户而言,本地部署仍然是一个值得尝试的选择。我认为,随着技术的进一步普及和工具的简化,未来会有更多人能够轻松地利用这类技术来提升工作效率和个人创造力。
采用技嘉X870AELITEWE7ICE主板,搭配AMD锐龙9950X3D和AORUS GeForce RTX5090 DMASTER ICE显卡以及32G×64GB内存的配置,在运行DeepSeek时完全游刃有余。就消费级平台而言,这样的组合已经接近性能极限,最多只需将内存容量提升至128GB,便有望应对更大规模的模型任务。整体来看,顶级消费级平台在本地部署方面的体验极为出色,建议有条件的朋友可以亲自试一试。
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
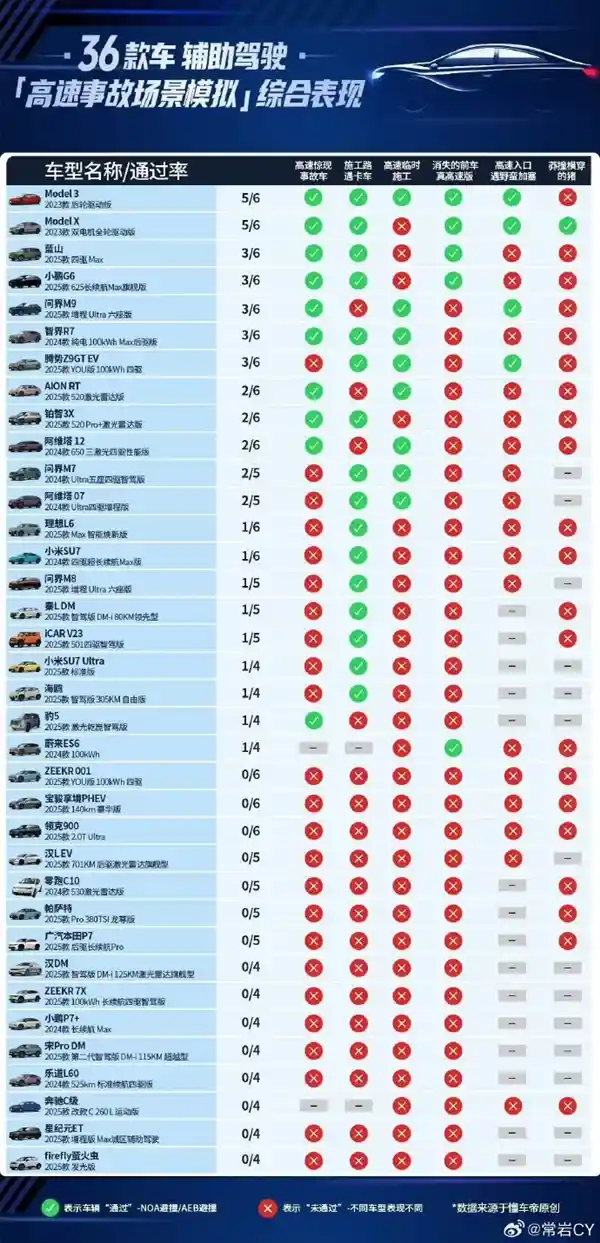
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
