《 Meta助推数字盗版风暴:三成AI训练书籍遭恶意传播 》
元宇宙陷阱:三成AI训练资料被盗版病毒席卷
3月27日消息,据科技媒体WinBuzzer报道,最新研究指出,Meta在数字图书盗版传播中的角色比预想的更为严重。这一发现无疑令人震惊,也引发了对大型科技公司在知识产权保护方面责任的深刻反思。 Meta作为全球领先的社交媒体平台,本应承担起更多维护网络环境的责任,尤其是在涉及版权保护的关键领域。然而,此次研究的结果却显示出其在打击盗版行为上的不足。这不仅损害了创作者的合法权益,也可能对整个出版行业的健康发展造成负面影响。希望Meta能够正视问题,加强平台监管,与各方共同努力,构建更加健康有序的互联网生态。同时,这也提醒我们,作为用户,在享受便捷服务的同时,也需要增强版权意识,共同抵制任何形式的侵权行为。
据消息透露,Meta公司被曝利用LibGen、Z-Library等“影子图书馆”中的盗版书籍来训练其AI模型,同时通过BitTorrent平台重新上传了大约30%的已下载书籍,这在客观上延长了盗版作品的传播时间。
专家指出,尽管BitTorrent默认采用分片上传机制,但有数据显示Meta的上传流量远高于正常水平,这可能使其变相充当了盗版传播的网络节点。
今年2月的消息显示,Meta在提交给法庭的文件中表示,尽管该公司从“影子图书馆”中下载了总计82TB的盗版版权资料以用于训练其LLaMA人工智能模型,但公司内部员工已经采取相关措施,确认在下载过程中并未对任何文件进行“种子分享(seeding)”。
不过最新研究指出的二次上传行为可能颠覆这一论点,澳大利亚前总理马尔科姆・特恩布尔发现著作被盗用,斥其“极度不安”,美国普利策奖得主迈克尔・夏邦等已提起诉讼,法国出版商指控 Meta 的行为是“对版权作品的大规模掠夺”。
欧盟委员会已经对此事展开关注,可能会根据《欧盟AI法案》对相关行为进行严厉处罚。如果法院最终裁定Meta必须为其训练数据获取正式授权,这将对AI行业的数据获取方式产生深远影响。目前,案件的具体结果尚不明朗,但这一版权争议无疑将成为数字时代知识产权保护的重要标志性事件。
相关阅读:
《Meta 为使用盗版素材训练 AI 辩护:下载不分享即合法》
《Meta 深陷盗版泥潭,邮件曝光 81.7 TB AI 训练数据黑幕》
《Meta 遭遇版权诉讼,扎克伯格被指亲自批准 AI 团队用盗版书训练模型》
人工智能最新资讯

2025-07-26 12:29:25
2025-07-26 11:31:19

2025-07-26 11:24:52

2025-07-26 11:05:46

2025-07-26 10:23:37

2025-07-26 10:23:03

2025-07-26 10:22:44

2025-07-26 10:18:42

2025-07-26 10:18:41

2025-07-26 10:16:31

2025-07-26 10:12:33

2025-07-26 10:12:30

2025-07-26 10:12:00

2025-07-26 10:11:24

2025-07-25 09:21:14

2025-07-25 09:20:36
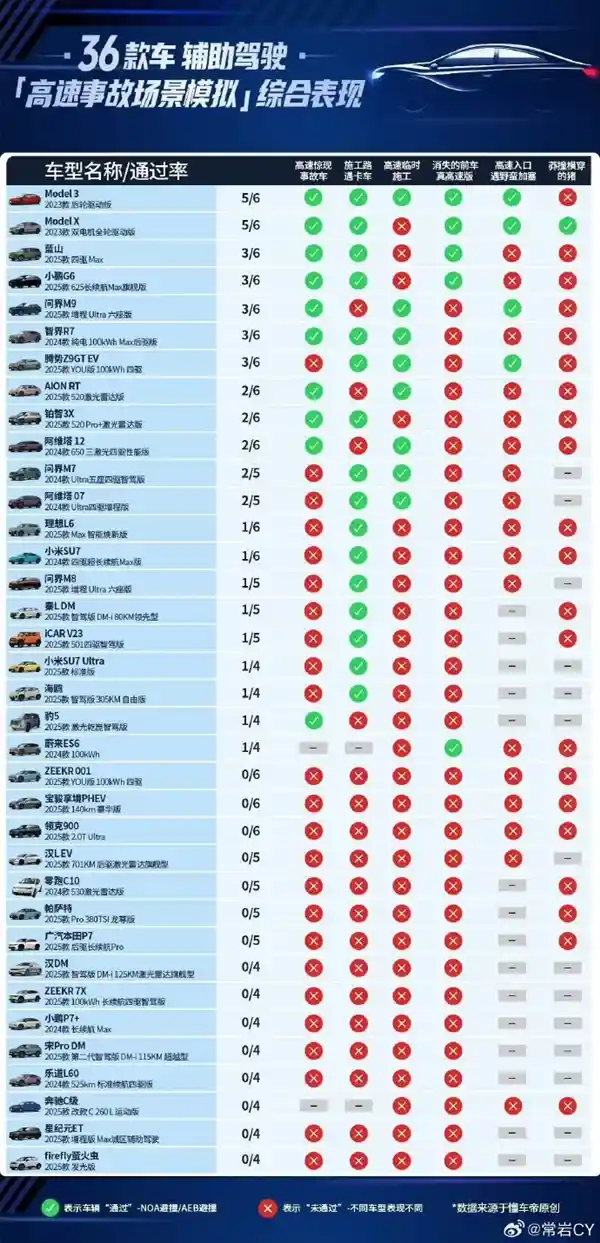
2025-07-25 09:00:17
2025-07-25 08:52:01
2025-07-25 08:42:47

2025-07-25 08:41:38

2025-07-25 08:24:04

2025-07-25 08:18:03

2025-07-25 08:02:51

2025-07-25 07:57:04
