豆包发布首个多语言类SWE数据集,助力大模型修Bug能力提升
语言创新,数据助力,打造超级修Bug大军!
4月10日消息,今日,字节跳动豆包大模型团队对外发布了一个全新的多语言类SWE数据集——Multi-SWE-bench,该数据集旨在助力大模型“自动修Bug”能力的评估与优化,并正式对外开放源代码。

Multi-SWE-bench作为SWE-bench的升级版,首次将评测范围扩展至Python之外的七种主流编程语言,包括Java、Go、Rust、C、C++、TypeScript和JavaScript,这一举措标志着它成为首个真正意义上覆盖全栈开发领域的评测基准。这种全面性不仅为开发者提供了更广阔的视角,也为企业在选择技术栈时提供了更为科学的参考依据。 在我看来,Multi-SWE-bench的推出恰逢其时。随着软件开发行业的快速发展,单一语言或技术已难以满足复杂的业务需求。尤其对于跨平台应用而言,能够熟练运用多种编程语言的全栈工程师变得愈发抢手。而Multi-SWE-bench通过提供统一标准下的性能对比,无疑将推动整个行业向着更加规范化、标准化的方向迈进。同时,它也为教育机构调整课程设置、培养符合市场需求的人才指明了方向。总之,这是一个值得肯定且令人期待的进步。
Multi-SWE-bench包含了1632个来自GitHub issue的真实案例,这些案例经过严格的标准测试和专业开发者的精心筛选,确保了每一个样本都拥有明确的问题描述、精准的修复补丁以及能够复现的运行环境。这一系列举措不仅为开发者提供了宝贵的参考资源,也为软件工程领域的研究奠定了坚实的基础。 我认为,这样一个高质量的数据集对于推动软件开发行业的进步具有重要意义。它不仅能帮助开发者快速定位和解决问题,还能够促进技术交流与协作,提升整个行业的效率。同时,这种高标准的数据整理方式也体现了对细节的关注和对质量的追求,值得其他项目借鉴学习。
豆包大模型团队计划让Multi-SWE-bench成为衡量大模型在多种主流编程语言和实际代码环境中自动编程能力的重要基准。这一举措有望引导大模型的研发朝着更加实用化和工程化的方向迈进。 在我看来,这一计划具有深远的意义。随着人工智能技术的不断进步,大模型的应用场景日益广泛,而编程能力无疑是其中至关重要的一环。通过设立这样一个全面且系统的评测基准,不仅能够帮助开发者更好地评估和优化他们的模型性能,还能促使整个行业关注那些真正贴近实际需求的技术创新。未来,我们期待看到更多基于此类标准开发出的产品能够在工业界发挥更大的作用,并为用户带来更加高效便捷的服务体验。
团队表示,Multi-SWE-bench相较于传统专注于单一Python语言的任务设计,更加贴合现实中多语言协同开发的实际场景,这使得它在评估模型“自动化软件工程”能力时更具参考价值。这一转变不仅反映了技术发展的新趋势,也揭示了开发者们在面对复杂项目时需要跨越语言障碍的真实需求。在我看来,这种调整不仅是对现有技术的一次重要升级,更是对未来软件开发模式的一种前瞻性探索。随着全球化的深入和技术交流的加速,掌握多种编程语言的工具和框架将成为工程师们的必备技能。因此,Multi-SWE-bench所代表的方向无疑为行业指明了一个值得追求的目标。
人工智能最新资讯

2025-09-09 10:53:20

2025-09-09 10:26:34

2025-09-09 10:22:01

2025-09-09 10:00:54

2025-09-09 09:47:55

2025-09-09 09:41:51

2025-09-09 09:31:15
2025-09-09 09:20:45

2025-09-09 08:45:29
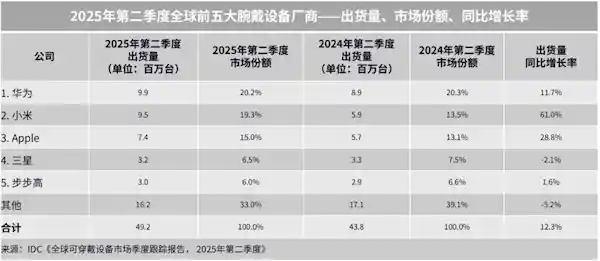
2025-09-09 08:43:24

2025-09-09 08:43:10

2025-09-09 08:42:10

2025-09-09 08:41:03

2025-09-09 08:35:42

2025-09-09 08:32:38
2025-09-09 08:31:08

2025-09-09 08:29:09

2025-09-09 08:27:23

2025-09-09 08:25:57

2025-09-05 14:17:14

2025-09-05 14:03:29

2025-09-05 13:52:40

2025-09-05 12:55:16

2025-09-05 12:54:17
